

Vector Search Is Not a Strategy: The New Standard for Copilot Accuracy


This episode explains that vector search on its own is not a complete or reliable strategy for building accurate AI systems like Copilot. While many organizations rely on embeddings and vector databases to retrieve information, this approach often leads to inconsistent or misleading results.
The main problem is that vector search works by finding content that is mathematically similar, not necessarily correct or relevant in a business context. This creates situations where the system returns results that look right but are actually wrong, leading to hallucinations and reduced trust in AI outputs.
The episode highlights that the real issue is not the language model itself, but how information is retrieved. Even the most advanced AI will produce poor answers if it is given the wrong or low-quality data.
To improve accuracy, the episode recommends moving beyond pure vector search and adopting a more structured retrieval strategy. This includes combining different techniques such as keyword search, metadata filtering, and business rules to ensure the AI accesses the most relevant and precise information.
The key takeaway is that vector search should be seen as just one tool, not the foundation. Reliable Copilot systems require thoughtful design, where retrieval strategy plays a central role in delivering accurate and trustworthy results.






You need reliable answers when working with enterprise AI. Pure vector search often fails to deliver accuracy and context. Look at the numbers:
| AI Model / System Approach | BIRD Execution Accuracy (Approximate) |
|---|---|
| Pure Vector Search (RAG) on quantitative queries | 0% - 10% |
Hybrid retrieval, like Copilot’s new standard, combines vectors and keywords. This improves precision and trust. Modern tools use semantic reranking to prioritize relevant answers. You will see why Hybrid RAG is essential for business success.
Key Takeaways
- Pure vector search often lacks accuracy and context, leading to irrelevant results.
- Hybrid retrieval combines vector and keyword search, improving precision and trust in AI responses.
- Context loss in pure vector search can lead to poor business decisions; hybrid methods maintain important details.
- Compliance and security are enhanced with hybrid search, reducing risks of privacy violations.
- High latency in pure vector search can frustrate users; hybrid systems provide faster, more reliable answers.
- Hybrid RAG systems improve recall and accuracy, ensuring you find the right information every time.
- Using hybrid search helps organizations understand internal jargon, leading to more relevant results.
- Transitioning to hybrid RAG requires careful planning, data preparation, and ongoing monitoring for success.
Pure Vector Search Limitations

Precision Issues
Context Loss
You often need your AI to understand the full context of your queries. When you rely on pure vector search, the system can lose important details. Embedding models focus on semantic similarity, which means they may ignore critical metadata like audience or recency. This leads to context collapse. For example, if you search for "Python developers in San Francisco with 5+ years of experience," the system might return candidates from Seattle. The AI misses the exact location and experience requirements. ByteDance's testing showed only 58% relevant results for queries needing exact matches. You see how context loss can affect your business decisions.
Irrelevant Results
You expect accurate answers, but retrieval inaccuracies often occur. Vector embeddings must stay in sync with your source data, which changes frequently. Updating embeddings is costly and can cause inconsistencies. Precision issues lead to irrelevant or outdated information. Sometimes, the AI returns results that do not match your criteria, causing hallucinations. The lack of business logic prevents effective filtering by department or product. Biases in embeddings also impact search quality. You may find that the AI cannot understand relationships within your organization, making it harder to find the right information.
Compliance Challenges
Audit Risks
Regulated industries face strict requirements. Attackers can exploit the vector search process by crafting targeted queries to infer sensitive information. If someone gains access to storage, they can exfiltrate the entire dataset. This creates offline inference risks. You must protect your data from these threats.
Regulatory Concerns
| Layer | Description |
|---|---|
| Application | Attackers can exploit the vector search process by crafting targeted queries to infer sensitive information. |
| Storage | If attackers access the storage, they can exfiltrate the entire dataset, leading to offline inference attacks. |
| Regulatory Risk | Both attack vectors pose significant privacy violations and regulatory risks, such as GDPR and HIPAA compliance issues. |
You must comply with regulations like GDPR and HIPAA. Privacy violations can lead to fines and loss of trust. Pure vector search does not always provide the controls needed for compliance.
Performance Bottlenecks
Scaling Problems
You want your AI to handle large datasets. Research shows that vector similarity search accuracy drops by 12% at 100,000 pages. As your data grows, the system becomes unreliable. Vector search treats each query in isolation, missing past interactions and complex relationships. Accuracy collapses to 20-30% on intricate tasks. Static embeddings fail to capture evolving information, leading to outdated decisions.
Latency
| Impact Area | Description |
|---|---|
| User Experience | High latency leads to delays that frustrate users and degrade satisfaction. |
| System Throughput | Increased latency can reduce the number of queries processed per second. |
| Real-Time Decision-Making | Latency affects the timeliness of decisions, potentially leading to poor outcomes. |
| Retrieval Quality | Systems may compromise on accuracy, resulting in smaller top-K values and reduced precision. |
| Optimization Techniques | To meet performance SLAs, systems may use aggressive caching and approximate nearest neighbor shortcuts, which can degrade retrieval precision and recall. |
You need fast answers. High latency slows down your AI, making users unhappy and reducing system throughput. Real-time decisions become harder. To speed things up, systems may cut corners, which lowers retrieval quality and precision.
Tip: When you evaluate AI search tools, check how they handle context, compliance, and performance. These factors shape your results and impact your business.
Hybrid RAG: The New Standard
Hybrid RAG has become the new benchmark for enterprise AI search. You now see organizations like m365.fm’s Copilot adopting this approach to deliver reliable, accurate results. This method combines the strengths of vector embeddings and keyword search, such as BM25, to address the challenges of trust, precision, and domain-specific language.
Vector and Keyword Integration
User Intent vs. Exact Language
You want your AI to understand what you mean, not just what you say. Hybrid RAG uses semantic search to capture your intent, even when you phrase things differently. At the same time, keyword search ensures the system does not miss exact terms that matter for your business. For example, if you ask about "quarterly revenue," the system recognizes both the concept and the specific phrase. This dual approach helps you get answers that match your needs, whether you use common language or specialized terms.
Hybrid retrieval combines keyword and semantic search, which improves the quality of results and leads to more accurate AI responses. You experience fewer repeated queries and faster first-time resolution. This builds trust in AI-driven decisions. The quality of AI responses links directly to the quality of the retrieved context, so you receive consistent answers and fewer escalations.
Handling Internal Jargon
Every organization has its own language. Hybrid RAG addresses this by using both semantic similarity and exact keyword matching. The system can use synonym dictionaries tailored to your industry, so it finds documents with any relevant term. If your company uses unique acronyms or product names, hybrid search ensures these terms are not lost. You get results that reflect your internal jargon and domain-specific terminology. This balance between semantic and keyword methods means you do not miss critical information.
Hybrid search optimizes retrieval by balancing semantically relevant content with exact matches. You benefit from a system that understands both complex intent and the specific language your team uses.
Semantic Reranking Layer
Prioritizing Relevant Answers
After retrieving a broad set of candidate documents, hybrid RAG uses a semantic reranking layer. This step acts as a filter. The system scores and reorders the results based on how relevant they are to your query. You see the most useful answers at the top, even if they were not the first ones found. This process helps you find the right information quickly, especially when you need to make important decisions.
Semantic reranking plays a crucial role in hybrid RAG systems. It uses a cross-encoder reranker to identify and promote relevant passages that may not have been among the top-ranked items. This method enhances the overall answer relevance and ensures you get the best possible response.
Moving Beyond Similarity Scores
You need more than just similar words. Hybrid RAG moves past basic similarity scores by evaluating the true relevance of each result. The system considers factors like context, factual accuracy, and grounding. This approach reduces the risk of hallucinations and ensures you receive answers you can trust.
Here are some common metrics used to evaluate the effectiveness of semantic reranking layers in enterprise AI search:
| Metric | Description |
|---|---|
| Precision | Measures how many retrieved results are relevant. |
| Recall | Measures how many relevant results were retrieved. |
| Mean Reciprocal Rank (MRR) | Assesses the quality of ranking based on the position of the first relevant result. |
| Normalized Discounted Cumulative Gain (nDCG) | Evaluates ranking quality by considering the position of relevant results. |
| User Satisfaction Surveys | Collects feedback on user experience and satisfaction. |
| Click-Through Rates (CTRs) | Measures the effectiveness of search results based on user clicks. |
| Factual Accuracy | Evaluates the correctness of the information retrieved. |
| Grounding Score | Assesses how well the retrieved information is grounded in the context. |
| Hallucination Rate | Measures the frequency of incorrect or fabricated information in results. |
Note: By using these metrics, you can measure the performance of your hybrid RAG system and ensure it meets your business needs.
Hybrid RAG stands out as the new standard because it brings together the best of both worlds. You gain trust, precision, and the ability to handle complex, domain-specific queries. This approach helps you move from experimental projects to reliable, production-grade AI systems.
Hybrid Search Benefits for Enterprises
Improved Recall and Accuracy
You want your enterprise AI to find the right information every time. Hybrid retrieval gives you better recall and accuracy than using only one method. By combining vector and keyword search, you get results that match both your intent and the exact words you use. This approach helps you find answers that are both relevant and precise.
Look at the numbers. In enterprise tasks like regulatory question answering, hybrid search systems show clear improvements over single-method systems. The table below compares different search methods on real-world datasets:
| System | Task / Dataset | Recall@10 | MAP / NDCG@10 | Note |
|---|---|---|---|---|
| BM25 (vanilla) | Regulatory QA | 0.7611 | 0.6237 | |
| Dense (fine-tuned) | Regulatory QA | 0.8103 | 0.6286 | |
| Hybrid (α=0.65) | Regulatory QA | 0.8333 | 0.7016 | ≈+7 pp Gain |
| RRF(BM25,NPR) | TREC-COVID | — | 52.32 (R@1K) | +48% rel. over dense only |
| DAT (LLM-tuned) | SQuAD | 0.8740 | — | +7.5% over fixed hybrid |
| LightRetriever hybrid | BEIR | — | 54.4 nDCG@10 | 95% of full LLM baseline |
| COS-Mix hybrid | Proprietary | 0.77 | — | Contextual Precision 0.98 |
You can also see the improvement in this chart:
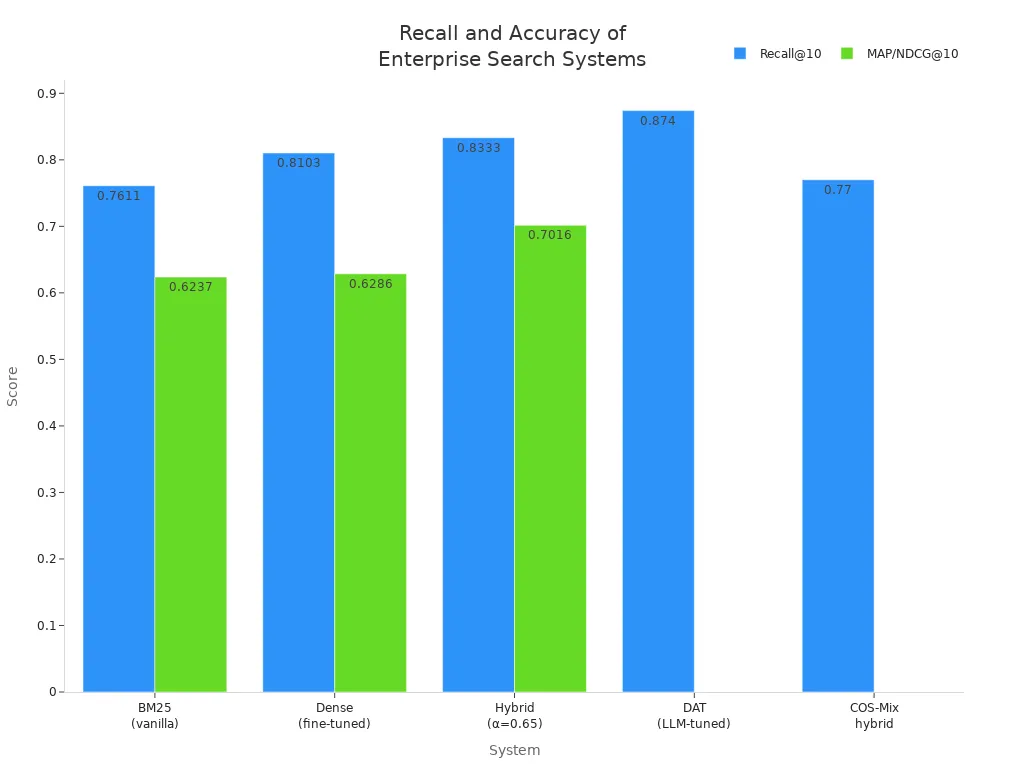
Hybrid RAG systems help you achieve higher recall and accuracy. This means you get more relevant results and fewer missed answers.
Enhanced Context and Insights
You need your AI to understand not just what you ask, but also the context behind your questions. Hybrid search uses both graph and vector methods to give you results that are precise and meaningful. This approach solves the problem of missing technical terms or internal jargon that pure vector search often faces.
- If you are a developer searching for "authentication middleware," you will find exact function names and related security documents.
- If you work in support and look for "database connection timeout," you will see the exact error code and helpful troubleshooting guides.
Hybrid search also improves the retrieval of internal knowledge. You get answers from trusted and verified sources. This builds credibility and trust in your AI system. By combining graph search for filtering and vector search for finding similar articles, you receive reliable and explainable results. You can make better decisions because you have the right context and deeper insights.
Compliance and Security
You must protect your data and follow strict rules. Hybrid search gives you better compliance and security than pure vector search. The table below shows how hybrid search compares:
| Feature | Hybrid Search | Pure Vector Search |
|---|---|---|
| Accuracy | Combines semantic relevance and relational context | Often returns irrelevant or hallucinated results |
| Explainability | Provides explainable AI outputs | Lacks contextual accuracy |
| Compliance and Security | Ensures contextual accuracy for compliance needs | May miss crucial relationships |
Hybrid search ensures your results are accurate and explainable. You can meet compliance needs because the system understands both the context and the relationships in your data. This reduces the risk of missing important connections and helps you stay secure.
Tip: When you choose an AI search solution, look for hybrid RAG systems. They offer better performance, stronger compliance, and more reliable answers for your business.
Cost Efficiency
You want your enterprise AI to deliver value without breaking the bank. Hybrid search offers a cost-efficient approach that helps you optimize your resources and reduce unnecessary expenses. When you use hybrid retrieval, you automate the search process. This automation lowers the need for manual data management and cuts operational costs. You spend less time sorting through information, and your team can focus on more important tasks.
Hybrid search also improves performance by using both vector and keyword methods. Keyword search algorithms do not rely on expensive GPUs, so you save on cloud costs related to storage and computation. You can implement hybrid RAG with reduced memory usage compared to pure semantic search engines. This means you pay less for infrastructure while maintaining high-quality results.
You benefit from enhanced efficiency and productivity. AI search solutions streamline your business operations, making your workflow more fiscally responsible. You avoid the high costs that come with maintaining large-scale semantic similarity models. Hybrid systems balance semantic and keyword approaches, so you get accurate answers without overspending.
Here is a quick overview of how hybrid search compares to pure vector or semantic methods in terms of cost:
| Feature | Hybrid Search | Pure Vector Search | Pure Semantic Search |
|---|---|---|---|
| Memory Usage | Lower | Higher | Higher |
| GPU Requirement | Minimal | Moderate | High |
| Cloud Storage Cost | Reduced | Increased | Increased |
| Manual Data Management | Automated | Manual | Manual |
| Productivity Impact | High | Moderate | Moderate |
Tip: You can maximize your budget by choosing hybrid RAG. This approach gives you reliable context and performance while keeping your operational costs low.
Hybrid retrieval helps you scale your AI solutions efficiently. You avoid bottlenecks and maintain consistent results as your data grows. By combining semantic and keyword search, you ensure that your system remains cost-effective and sustainable. You can trust this method to deliver the right answers without sacrificing your financial goals.
Hybrid Graph-Vector RAG Techniques
Graph and Semantic Retrieval
You want your enterprise search to deliver both accuracy and depth. Hybrid graph-vector rag achieves this by combining the strengths of graphrag with semantic and keyword-based retrieval. Graphrag uses structured relationships between data points, while semantic search uncovers meaning and intent. When you integrate graph structures with BM25 and vector search, you get a system that excels at both precision and context.
Consider this table that highlights the impact of this integration:
| Evidence Type | Description |
|---|---|
| Hybrid RAG | Combines graph-based and vector-based retrieval for better Q&A performance. |
| Knowledge Graphs | Fusing graphs with vector rag improves answer faithfulness and context. |
| Explainability | BM25 adds transparency, supporting explainable AI for your team. |
Hybrid graph-vector rag reduces risk by covering blind spots. For example, if your legal team searches for “termination rights under insolvency risk,” sparse retrieval finds the exact phrase, while semantic methods surface related concepts like “contract dissolution.” This dual approach ensures you do not miss critical information.
Structured Knowledge Representation
You need your AI to support both fact-finding and advanced reasoning. Hybrid graph-vector rag provides this by using graphrag to organize knowledge in a structured way. This structure supports flexible and transparent search. You can adapt to new business needs and integrate different data sources with ease.
Here are some benefits of structured knowledge representation in hybrid graph-vector rag:
- Supports both simple lookups and complex reasoning tasks.
- Offers more flexibility than pure graphrag systems.
- Delivers greater transparency than traditional vector-only solutions.
- Makes it easier to maintain and refresh your data.
- Enables reusable knowledge graphs across teams, boosting collaboration.
This approach helps you build trust in your AI systems and ensures your data stays relevant.
Privacy and Performance
You must protect sensitive information and maintain high performance. Hybrid graph-vector rag addresses privacy by supporting privacy-preserving techniques. Financial institutions use these systems to comply with regulations and keep client data safe. For example, a bank can use differential privacy to answer customer questions about financial products without exposing personal details.
Performance also matters. Hybrid graph-vector rag balances recall and accuracy, which is crucial for financial and regulated industries. On-device solutions may run slightly slower than cloud-based ones, but they offer better privacy. Some privacy methods, like homomorphic encryption, can slow things down, but hybrid graph-vector rag lets you choose the right balance for your needs.
Tip: When you use hybrid graph-vector rag, you gain a system that delivers accurate, explainable, and secure results—helping your business make better decisions every day.
RAG in Real-World Enterprise Use Cases
Financial Services
You see rapid changes in financial services. Companies use rag to improve their operations and customer experience. Many organizations rely on ai to process large amounts of proprietary data. You can look at the table below to understand how different companies benefit from this technology.
| Company | Application Description | Benefits |
|---|---|---|
| Rocket Companies | Streamlined mortgage processing by integrating proprietary financial data. | Reduced processing times and improved customer experiences. |
| Shorenstein Properties | Automated file tagging and organized proprietary data more efficiently. | Improved data accessibility and management, leading to increased operational efficiency. |
| Cohere | Ensured AI systems cite their sources, integrating external texts for verification. | Reduced errors and enhanced reliability and transparency of AI-generated content. |
| NVIDIA | Connected large language models with proprietary customer data and authoritative research. | Enabled accurate responses to user queries, enhancing productivity and reducing hallucinations. |
| IBM | Equipped models with specific information for domain-specific applications. | Improved accuracy and relevance in AI-generated responses across different sectors. |
You can see how these companies use hybrid retrieval to reduce errors and speed up processes. This approach helps you manage sensitive financial information and deliver reliable answers to your clients.
Healthcare
You want your healthcare system to provide accurate and fast diagnoses. Hybrid retrieval improves patient care by connecting live patient records with the latest medical research. You can see the benefits in these examples:
- Diagnostic processes become faster when you combine patient histories with up-to-date medical insights.
- Clinicians access both patient data and recent studies, which improves diagnostic accuracy.
- According to McKinsey, diagnosis time dropped by 20% after implementing hybrid retrieval in medical settings.
You gain better outcomes for patients and more confidence in your healthcare decisions.
Legal and E-Discovery
You need to handle complex legal queries and manage large volumes of documents. Hybrid retrieval helps you find relevant information quickly and accurately. The table below shows how different use cases benefit from this approach.
| Use Case | Description |
|---|---|
| Enterprise sales and account management | Retrieves and validates data across multiple systems, ensuring accuracy in contract status queries. |
| Technical support and documentation | Analyzes logs and retrieves relevant documentation, giving support agents accurate information for troubleshooting. |
| Financial analysis and reporting | Handles sequential dependencies in data retrieval, allowing for comprehensive financial comparisons and variance analysis. |
| Ecommerce product discovery | Decomposes complex customer queries into multiple retrieval needs, ensuring all constraints are met for product searches. |
You improve efficiency and reduce the risk of missing important details. Hybrid retrieval supports your legal team by providing explainable and trustworthy results.
Tip: You can use hybrid retrieval in many industries to solve real-world problems and deliver better outcomes for your business.
Customer Support
You want your customer support team to solve problems quickly and accurately. Hybrid RAG technology helps you achieve this goal by combining the strengths of vector and keyword search. This approach allows your AI-powered support agents to understand the context of each customer’s request. The system can cross-reference a customer’s history, find similar past cases, and suggest solutions that fit the specific situation.
An AI-powered support agent that understands context can cross-reference the customer’s history, identify similar past cases, and propose a solution tailored to their specific situation. This reduces costly escalations, accelerates resolution times, and turns customer support into a proactive, value-driven function.
When you use RAG in your support operations, you notice several key improvements:
- Reduced operational overhead
- Fewer errors
- Enhanced customer service quality
- Shorter search-to-decision cycles
You no longer need to rely on manual searches or guesswork. The AI retrieves relevant information from your knowledge base, previous tickets, and documentation. This means your agents spend less time searching and more time helping customers. You see faster response times and higher satisfaction rates.
Hybrid RAG also helps your team handle complex or unusual questions. If a customer asks about a rare issue, the system finds similar cases and provides step-by-step solutions. Your agents feel more confident because they have access to the right information at the right time. This reduces the number of escalations to higher-level support.
You can also use RAG to automate responses for common questions. The AI suggests accurate answers based on your company’s policies and past resolutions. This frees up your team to focus on more challenging problems. You improve efficiency and keep your support costs under control.
Customer support teams benefit from better insights as well. You can track which issues come up most often and identify trends. This helps you improve your products and services over time. Your customers notice the difference. They get faster, more accurate answers and feel valued by your company.
Tip: When you use hybrid RAG for customer support, you transform your help desk into a proactive, efficient, and customer-focused operation.
Transitioning to Hybrid RAG
Migration Steps
You can move to a hybrid approach by following a clear set of steps. Start by assessing your current search system and identifying gaps in accuracy or context. Next, select a platform or tool that supports both vector and keyword search. Plan your migration in phases. Begin with a pilot project on a small dataset. Test the new system and compare results with your old approach. Involve your team early so everyone understands the benefits and changes. Document each step and create a feedback loop for continuous improvement.
Data Preparation
Preparing your data is essential for a successful transition. You need a strategy that focuses on valuable sources and builds a repeatable pipeline. Follow these best practices:
- Create a data preparation strategy. Identify which sources matter most for your business.
- Choose a vector database. This helps you use embeddings for effective retrieval.
- Develop a retrieval strategy. Combine keyword and semantic similarity methods to improve performance.
- Ensure security and compliance. Protect sensitive information at every stage.
- Optimize prompt engineering. Define templates and formats for clear communication with your language model.
- Govern your RAG architecture. Monitor and manage your knowledge base to keep it accurate and relevant.
A well-prepared dataset supports both the semantic and keyword sides of your hybrid approach. This foundation helps you get the most out of your new system.
Monitoring and Improvement
Once you launch your hybrid RAG system, you need to monitor its performance. Track key indicators like success rate, response time, and consistency. Use real-time dashboards and anomaly detection tools to spot issues quickly. Collect user feedback through in-app tools that let users rate responses or report problems. Analyze this feedback to find trends and prioritize improvements.
You should also measure how much CPU and GPU your system uses. Keep an eye on the cost of API calls and check the balance between performance and expenses. Use A/B testing and human review to refine your models. Active learning systems can help you use feedback to fine-tune your approach over time.
Tip: Regular monitoring and user feedback keep your hybrid RAG system accurate, efficient, and trusted by your team.
Avoiding Pitfalls
You want your transition to hybrid RAG to succeed. Many organizations face challenges during this process. You can avoid common mistakes by planning carefully and staying aware of potential risks.
Common Pitfalls When Moving to Hybrid RAG
| Pitfall | Description | How to Avoid |
|---|---|---|
| Incomplete Data Mapping | Missing connections between old and new systems. | Map all data sources before launch. |
| Overlooking Security | Failing to update privacy controls. | Review and update security policies. |
| Ignoring User Feedback | Not listening to users during migration. | Collect feedback and adjust plans. |
| Poor Testing | Skipping thorough testing of hybrid features. | Test each feature with real data. |
| Lack of Training | Not preparing your team for new workflows. | Train staff and provide resources. |
You need to map your data sources. If you miss this step, your AI may return incomplete or inaccurate results. You should review your privacy and security policies. Hybrid RAG systems often require new controls to protect sensitive information. You must listen to your users. Their feedback helps you spot issues early and improve your system.
Tip: Always test your hybrid RAG features with real business data. This ensures your system works as expected and meets your needs.
You should train your team. Staff who understand the new workflows can use the system more effectively. Training reduces confusion and helps everyone adapt quickly.
Checklist for a Smooth Transition
- Map all data sources and connections.
- Update privacy and security controls.
- Collect user feedback during each phase.
- Test hybrid features with real-world scenarios.
- Provide training and support for your team.
You can use this checklist to guide your migration. Each step helps you avoid costly mistakes and keeps your project on track.
Watch for Hidden Risks
You may face hidden risks during your transition. For example, legacy systems can create compatibility issues. You should check for outdated formats or unsupported integrations. Hybrid RAG systems may also require new hardware or software. You need to plan for these changes.
Note: Regular reviews help you catch problems early. Schedule check-ins with your team and update your plan as needed.
You can avoid pitfalls by staying proactive. Careful planning, testing, and training make your transition smoother. You build a reliable hybrid RAG system that supports your business goals.
The Future of Hybrid RAG in Enterprise AI
Industry Trends
You see the enterprise AI landscape changing quickly. Hybrid RAG is now the production baseline for many organizations. You need accuracy, cost efficiency, and strong governance. Companies want precision retrieval at scale. They use targeted retrieval and adaptive pipelines to get the best results. Agentic orchestration is also growing. This means you can build complex workflows that fix themselves when errors happen. Composable modular ecosystems let you connect hybrid RAG with unified analytics platforms. You can see these trends in the table below:
| Trend Description | Key Focus Areas |
|---|---|
| Hybrid RAG as production baseline | Accuracy, cost efficiency, governance |
| Precision retrieval at scale | Targeted retrieval, adaptive pipelines |
| Agentic orchestration | Complex workflows, self-correcting reliability |
| Composable modular ecosystems | Integration with unified analytics platforms |
You notice that selecting the right RAG architecture is now a strategic decision. Enterprises want systems that deliver actionable insights, accountability, and adaptability. You must keep up with these trends to stay competitive.
Next-Gen Applications
You will see hybrid RAG power the next generation of enterprise AI tools. Neural search models will work together with graph-based systems. You can expect neural pipelines to handle both structured and unstructured data. Neural agents will automate research, compliance checks, and customer support. Neural document understanding will help you extract facts from contracts, emails, and reports. Neural-driven analytics will give you real-time insights from massive datasets. Neural-powered chatbots will answer questions using both neural and keyword signals. Neural workflows will connect different business units and speed up decision-making. Neural monitoring tools will track system health and alert you to problems. Neural security layers will protect sensitive information. Neural compliance engines will check for regulatory risks. Neural personalization will tailor results for each user. Neural summarization will condense long documents for quick review. Neural translation will break language barriers in global teams. Neural recommendation systems will suggest actions based on past behavior. Neural anomaly detection will spot unusual patterns in your data. Neural forecasting will predict trends and help you plan ahead. Neural optimization will fine-tune your business processes. Neural integration tools will connect with cloud and on-premises systems. Neural explainability features will show you why the AI made a decision. Neural feedback loops will let you improve the system over time. Neural benchmarking will help you measure performance. Neural collaboration tools will support teamwork across departments. Neural visualization will turn complex data into easy-to-read charts. Neural voice assistants will help you interact with your data hands-free. Neural edge computing will bring AI closer to where data is created. Neural federated learning will let you train models without sharing raw data. Neural privacy controls will keep your information safe. Neural auditing will track every action for compliance. Neural lifecycle management will keep your AI up to date. Neural deployment tools will make it easy to roll out new features. Neural innovation will drive the future of enterprise AI.
Note: As enterprises adopt AI-driven transformations, you will see RAG systems meet growing demands for information retrieval and actionable insights.
Preparing for Change
You need to prepare for the future of hybrid RAG. Start by building a roadmap for AI adoption. Train your team on neural and hybrid technologies. Invest in data quality and governance. Test new neural applications in small pilots before scaling up. Monitor industry trends and update your strategy often. Work with partners who understand neural search and hybrid RAG. Set clear goals for accuracy, cost, and compliance. Use feedback from users to improve your systems. Stay flexible so you can adapt to new neural innovations. You will build a foundation for sustainable, trustworthy AI in your organization.
Tip: Stay curious and keep learning. The future of enterprise AI belongs to those who embrace change and invest in neural-powered solutions.
You now see why hybrid RAG stands as the enterprise standard. You gain accuracy, trust, and business value when you move beyond pure vector search. Start by reviewing your current AI search tools. Explore solutions like Copilot from m365.fm to guide your transition. Take small steps, monitor results, and train your team. You prepare your organization for the future of search and build a foundation for sustainable, trustworthy AI.
FAQ
What is hybrid RAG in enterprise AI?
Hybrid RAG combines vector search and keyword search. You get both semantic understanding and exact matches. This approach helps you find accurate and relevant answers in your business data.
Why does pure vector search struggle with compliance?
Pure vector search often lacks explainability. You may find it hard to trace how the AI found an answer. This makes it difficult to meet strict compliance and audit requirements.
How does hybrid search improve accuracy?
Hybrid search uses both intent and exact terms. You get results that match your meaning and your words. This dual method reduces irrelevant answers and increases precision.
Can hybrid RAG handle internal company jargon?
Yes. Hybrid RAG recognizes your unique terms and acronyms. You see results that reflect your organization’s language and context.
Is hybrid RAG more expensive to run?
No. Hybrid RAG often reduces costs. You use fewer resources by combining efficient keyword search with targeted vector retrieval. This balance saves on cloud and hardware expenses.
How do I start moving to hybrid RAG?
You begin by reviewing your current search tools. Choose a platform that supports both vector and keyword methods. Test with a small dataset before scaling up.
What industries benefit most from hybrid RAG?
You see strong results in finance, healthcare, legal, and customer support. Any industry that needs accuracy, compliance, and trust can benefit from hybrid RAG.
Does hybrid RAG help prevent AI hallucinations?
Yes. Hybrid RAG uses semantic reranking and grounding. You get answers based on real data, which lowers the risk of hallucinated or made-up information.
🚀 Want to be part of m365.fm?
Then stop just listening… and start showing up.
👉 Connect with me on LinkedIn and let’s make something happen:
- 🎙️ Be a podcast guest and share your story
- 🎧 Host your own episode (yes, seriously)
- 💡 Pitch topics the community actually wants to hear
- 🌍 Build your personal brand in the Microsoft 365 space
This isn’t just a podcast — it’s a platform for people who take action.
🔥 Most people wait. The best ones don’t.
👉 Connect with me on LinkedIn and send me a message:
"I want in"
Let’s build something awesome 👊
1
00:00:00,000 --> 00:00:01,480
The industry sold us a myth.
2
00:00:01,480 --> 00:00:03,360
They told us that embeddings were the silver bullet
3
00:00:03,360 --> 00:00:04,880
for enterprise intelligence.
4
00:00:04,880 --> 00:00:07,400
You built the vector database, you ingested the documents,
5
00:00:07,400 --> 00:00:10,760
you spent the budget, and yet, the hallucinations haven't stopped.
6
00:00:10,760 --> 00:00:12,960
In reality, mathematical similarity is not
7
00:00:12,960 --> 00:00:14,720
the same thing as business relevance.
8
00:00:14,720 --> 00:00:16,440
We fell into the top K-trap.
9
00:00:16,440 --> 00:00:18,320
This is the moment where your co-pilot retrieves
10
00:00:18,320 --> 00:00:21,440
the most similar data point in the high-dimensional space.
11
00:00:21,440 --> 00:00:23,160
But that data happens to be 100% wrong
12
00:00:23,160 --> 00:00:24,680
for the specific task at hand.
13
00:00:24,680 --> 00:00:27,720
Because in 2026, proximity is a cheap proxy for truth.
14
00:00:27,720 --> 00:00:30,600
If your Rage project is currently stalling in the pilot phase,
15
00:00:30,600 --> 00:00:32,520
it's not because the AI is dumb.
16
00:00:32,520 --> 00:00:35,800
It's because your retrieval strategy is built on an illusion against
17
00:00:35,800 --> 00:00:38,120
the structural failure of pure vector models.
18
00:00:38,120 --> 00:00:40,040
Vector search is a commodity layer.
19
00:00:40,040 --> 00:00:42,520
In the architecture of a modern AI system,
20
00:00:42,520 --> 00:00:45,000
it's the basement of the stack, not the penthouse.
21
00:00:45,000 --> 00:00:46,720
But we've been treating it like the brain.
22
00:00:46,720 --> 00:00:49,160
The fundamental flaw in high-dimensional embeddings
23
00:00:49,160 --> 00:00:51,360
is that they are fuzzy by design.
24
00:00:51,360 --> 00:00:53,360
They represent concepts as coordinates.
25
00:00:53,360 --> 00:00:56,280
That works beautifully when you're looking for vibes or general topics.
26
00:00:56,280 --> 00:00:58,400
But work doesn't happen in the land of vibes.
27
00:00:58,400 --> 00:00:59,960
Work happens in the land of specifics.
28
00:00:59,960 --> 00:01:01,920
And this is where the pure vector model breaks.
29
00:01:01,920 --> 00:01:03,560
Vector struggle with exact terms.
30
00:01:03,560 --> 00:01:06,760
Think about product codes, SKUs, legal terminology,
31
00:01:06,760 --> 00:01:08,720
internal project code names.
32
00:01:08,720 --> 00:01:11,960
To a vector model, project Phoenix and project Firebird
33
00:01:11,960 --> 00:01:13,600
might look mathematically identical
34
00:01:13,600 --> 00:01:15,560
because they share a semantic cluster.
35
00:01:15,560 --> 00:01:18,840
But to your finance team, they represent two entirely different budgets.
36
00:01:18,840 --> 00:01:20,640
When you rely solely on dense embeddings,
37
00:01:20,640 --> 00:01:24,080
you are essentially asking the AI to guess based on a neighborhood.
38
00:01:24,080 --> 00:01:27,000
The result, a 27% error rate in business outputs.
39
00:01:27,000 --> 00:01:28,520
That's not just a technical metric.
40
00:01:28,520 --> 00:01:32,040
That error rate translates to 1.8 hours of employee time
41
00:01:32,040 --> 00:01:34,040
wasted every single week.
42
00:01:34,040 --> 00:01:36,480
People aren't using co-pilot to work faster.
43
00:01:36,480 --> 00:01:37,960
They're using it to generate drafts
44
00:01:37,960 --> 00:01:40,240
that they then have to spend two hours fact checking
45
00:01:40,240 --> 00:01:42,080
because the retrieval set was noisy.
46
00:01:42,080 --> 00:01:43,200
We have an accuracy crisis.
47
00:01:43,200 --> 00:01:44,760
And it's not an LLM problem.
48
00:01:44,760 --> 00:01:47,960
You can't fix this by switching from GPT-4 to GPT-5
49
00:01:47,960 --> 00:01:49,680
or moving to a larger context window.
50
00:01:49,680 --> 00:01:51,440
It's a retrieval engineering problem.
51
00:01:51,440 --> 00:01:52,560
We made a massive assumption.
52
00:01:52,560 --> 00:01:54,400
We assumed the math would handle the context.
53
00:01:54,400 --> 00:01:57,640
We thought if we just turned every document into a list of numbers,
54
00:01:57,640 --> 00:01:59,160
the relationships would emerge.
55
00:01:59,160 --> 00:02:00,760
But context is structural.
56
00:02:00,760 --> 00:02:02,200
It's not just probabilistic.
57
00:02:02,200 --> 00:02:05,760
In an enterprise environment, the meaning of a document isn't just in the words.
58
00:02:05,760 --> 00:02:06,920
It's in the metadata.
59
00:02:06,920 --> 00:02:07,880
It's in the permissions.
60
00:02:07,880 --> 00:02:11,440
It's in the specific versioning that a vector model completely ignores.
61
00:02:11,440 --> 00:02:13,640
When you search for the latest travel policy,
62
00:02:13,640 --> 00:02:17,040
a vector search finds the policy that sounds most like a travel policy.
63
00:02:17,040 --> 00:02:19,880
It doesn't necessarily find the one that was approved yesterday.
64
00:02:19,880 --> 00:02:21,840
It finds the most similar one.
65
00:02:21,840 --> 00:02:23,880
And if the most similar one is the 2022 version
66
00:02:23,880 --> 00:02:27,080
because it has more descriptive text, that's what your LLM gets,
67
00:02:27,080 --> 00:02:29,720
then the AI tells your employee they can book business class.
68
00:02:29,720 --> 00:02:31,840
Even though the new policy says economy only.
69
00:02:31,840 --> 00:02:34,440
That's a hallucination caused by bad data grounding.
70
00:02:34,440 --> 00:02:35,280
The model didn't lie.
71
00:02:35,280 --> 00:02:37,360
It just summarized the wrong pile of numbers.
72
00:02:37,360 --> 00:02:40,200
This is what happens when you use a model design for discovery
73
00:02:40,200 --> 00:02:41,840
and try to use it for precision.
74
00:02:41,840 --> 00:02:44,600
Vector search is excellent at finding the needle in the haystack
75
00:02:44,600 --> 00:02:46,240
if you don't care which needle you get.
76
00:02:46,240 --> 00:02:48,680
But in the enterprise, there is only one correct needle.
77
00:02:48,680 --> 00:02:50,240
The other nine are liabilities.
78
00:02:50,240 --> 00:02:53,240
We've reached the limit of what pure similarity can do for us.
79
00:02:53,240 --> 00:02:55,520
If we want to hit that 0.9 precision threshold
80
00:02:55,520 --> 00:02:57,360
that regulated industries require,
81
00:02:57,360 --> 00:02:59,720
we have to stop treating retrieval like a math problem
82
00:02:59,720 --> 00:03:02,280
and start treating it like an editorial problem.
83
00:03:02,280 --> 00:03:04,360
We need to move past the idea that close enough
84
00:03:04,360 --> 00:03:06,280
is acceptable for a system that is supposed
85
00:03:06,280 --> 00:03:08,200
to drive executive decision making.
86
00:03:08,200 --> 00:03:11,120
Because right now the top-k results you're feeding your co-pilot
87
00:03:11,120 --> 00:03:14,000
are just a collection of mathematically related noise.
88
00:03:14,000 --> 00:03:15,920
You're asking a reasoning engine to build a house
89
00:03:15,920 --> 00:03:17,520
on a foundation of sand.
90
00:03:17,520 --> 00:03:19,040
And then we wonder why the roof is leaking.
91
00:03:19,040 --> 00:03:22,520
The shift from 2025 to 2026 is the realization
92
00:03:22,520 --> 00:03:24,600
that embeddings are just the starting point.
93
00:03:24,600 --> 00:03:26,080
They are the maybe pile.
94
00:03:26,080 --> 00:03:28,760
To get to the yes pile, we need a different kind of logic.
95
00:03:28,760 --> 00:03:30,240
We need to reintroduce the very things
96
00:03:30,240 --> 00:03:32,000
we thought embeddings would replace.
97
00:03:32,000 --> 00:03:32,800
We need structure.
98
00:03:32,800 --> 00:03:34,560
We need lexical anchors.
99
00:03:34,560 --> 00:03:36,520
And most importantly, we need a supervisor
100
00:03:36,520 --> 00:03:38,600
who knows the difference between a similar answer
101
00:03:38,600 --> 00:03:39,520
and a correct one.
102
00:03:39,520 --> 00:03:42,560
Without that, your RAC project isn't an intelligence tool.
103
00:03:42,560 --> 00:03:46,080
It's just a very expensive, very fast way to be wrong.
104
00:03:46,080 --> 00:03:47,640
But here is where the model breaks.
105
00:03:47,640 --> 00:03:50,520
Because similarity is a cheap proxy for truth.
106
00:03:50,520 --> 00:03:52,760
The mathematical neighborhood is a dangerous place to live.
107
00:03:52,760 --> 00:03:54,840
We've relied on these dense clusters for too long,
108
00:03:54,840 --> 00:03:56,880
assuming that if two things are near each other,
109
00:03:56,880 --> 00:03:59,400
in a vector space, they must be related in a business sense.
110
00:03:59,400 --> 00:04:00,640
But they aren't.
111
00:04:00,640 --> 00:04:03,320
Similarity is just a reflection of word usage patterns.
112
00:04:03,320 --> 00:04:05,080
It is a cheap proxy for truth.
113
00:04:05,080 --> 00:04:07,720
And in 2026, the model breaks because we've stopped looking
114
00:04:07,720 --> 00:04:10,440
for related things and started needing verified things.
115
00:04:10,440 --> 00:04:12,560
When you move from a pilot to a production environment,
116
00:04:12,560 --> 00:04:13,680
the stakes change.
117
00:04:13,680 --> 00:04:15,120
The proxy is no longer enough.
118
00:04:15,120 --> 00:04:16,920
You need something that anchors the AI back
119
00:04:16,920 --> 00:04:19,240
into the actual language of your organization.
120
00:04:19,240 --> 00:04:21,640
You need the precision that we accidentally threw away
121
00:04:21,640 --> 00:04:23,680
when we went all in on embeddings.
122
00:04:23,680 --> 00:04:26,640
The hybrid standard, YBM25 still matters.
123
00:04:26,640 --> 00:04:29,280
If you look at the production baseline for 2026,
124
00:04:29,280 --> 00:04:30,480
the landscape has shifted.
125
00:04:30,480 --> 00:04:32,840
We aren't talking about experimental vector stores anymore.
126
00:04:32,840 --> 00:04:34,520
We're talking about the hybrid standard.
127
00:04:34,520 --> 00:04:35,880
The data is clear.
128
00:04:35,880 --> 00:04:38,520
72% of successful enterprise RAC systems
129
00:04:38,520 --> 00:04:40,600
have moved away from pure vector retrieval.
130
00:04:40,600 --> 00:04:42,280
They've implemented a dual path system
131
00:04:42,280 --> 00:04:44,000
that combines the meaning of vectors
132
00:04:44,000 --> 00:04:45,880
with the precision of keyword matching.
133
00:04:45,880 --> 00:04:48,760
Specifically, they've brought back the BM25 algorithm
134
00:04:48,760 --> 00:04:51,240
for those who haven't spent 20 years in search engineering.
135
00:04:51,240 --> 00:04:54,040
BM25 is the classic, sparse retrieval method.
136
00:04:54,040 --> 00:04:56,160
It's the logic that looks for exact word overlaps.
137
00:04:56,160 --> 00:04:59,080
It's the old way that we thought embeddings would kill.
138
00:04:59,080 --> 00:05:00,640
But it turns out the old way is the only thing
139
00:05:00,640 --> 00:05:02,080
that keeps the new way honest.
140
00:05:02,080 --> 00:05:04,440
When you combine these two, something interesting happens.
141
00:05:04,440 --> 00:05:07,280
You get a 17% recall gain across your entire data set.
142
00:05:07,280 --> 00:05:09,800
That 17% is the difference between an employee
143
00:05:09,800 --> 00:05:12,400
finding the answer in 10 seconds or giving up
144
00:05:12,400 --> 00:05:14,040
after three failed prompts.
145
00:05:14,040 --> 00:05:15,960
Think about what happens when you stop ignoring
146
00:05:15,960 --> 00:05:18,800
the specific words your users actually type.
147
00:05:18,800 --> 00:05:22,720
In a pure vector system, if a user types Form 10K 2025,
148
00:05:22,720 --> 00:05:24,720
the model might prioritize a general article
149
00:05:24,720 --> 00:05:27,400
about financial reporting because the vibe is similar.
150
00:05:27,400 --> 00:05:29,560
But with BM25 in the mix, the system
151
00:05:29,560 --> 00:05:33,200
sees that specific 10K and 2025 string.
152
00:05:33,200 --> 00:05:35,440
It recognizes that these aren't just concepts.
153
00:05:35,440 --> 00:05:36,880
They are lexical anchors.
154
00:05:36,880 --> 00:05:39,000
Hybrid retrieval allows the system to say,
155
00:05:39,000 --> 00:05:40,760
"I know you're interested in financial reports,
156
00:05:40,760 --> 00:05:42,360
but I also see you specifically asked
157
00:05:42,360 --> 00:05:43,800
for this exact document."
158
00:05:43,800 --> 00:05:46,360
It solves the out of domain query problem.
159
00:05:46,360 --> 00:05:49,240
This is the biggest hurdle for any pre-trained embedding model.
160
00:05:49,240 --> 00:05:50,880
Your vector model was likely trained
161
00:05:50,880 --> 00:05:52,880
on a general corpus of internet text.
162
00:05:52,880 --> 00:05:54,240
It knows what a contract is,
163
00:05:54,240 --> 00:05:57,280
but it doesn't know the specific jargon of your industry.
164
00:05:57,280 --> 00:05:59,560
It doesn't understand the proprietary acronyms
165
00:05:59,560 --> 00:06:01,080
used in your engineering department.
166
00:06:01,080 --> 00:06:02,480
It hasn't seen the internal shorthand
167
00:06:02,480 --> 00:06:05,080
your logistics team uses to describe shipping delays.
168
00:06:05,080 --> 00:06:07,600
To a general embedding model, those words are noise.
169
00:06:07,600 --> 00:06:09,120
They are out of domain.
170
00:06:09,120 --> 00:06:11,880
But to BM25, those words are signals.
171
00:06:11,880 --> 00:06:14,800
By running a keyword search alongside the vector search,
172
00:06:14,800 --> 00:06:16,120
you create a safety net.
173
00:06:16,120 --> 00:06:19,120
You ensure that if a user types a specific term
174
00:06:19,120 --> 00:06:20,720
that the embedding model doesn't understand,
175
00:06:20,720 --> 00:06:24,320
the system can still find the document based on the literal text.
176
00:06:24,320 --> 00:06:27,200
This is how you reach the 0.8 precision threshold.
177
00:06:27,200 --> 00:06:30,640
In 2025, we were happy if the AI was mostly right.
178
00:06:30,640 --> 00:06:34,160
In 2026, 80% accuracy is the bare minimum for entry.
179
00:06:34,160 --> 00:06:35,800
Hybrid is the first step toward that goal.
180
00:06:35,800 --> 00:06:37,560
It's about anchoring the AI in reality.
181
00:06:37,560 --> 00:06:39,000
Think of it as a dual check system.
182
00:06:39,000 --> 00:06:40,720
The vector path handles the intent.
183
00:06:40,720 --> 00:06:42,360
The what are they trying to do?
184
00:06:42,360 --> 00:06:44,160
The keyword path handles the facts.
185
00:06:44,160 --> 00:06:46,520
The what did they actually say?
186
00:06:46,520 --> 00:06:48,400
When both paths agree on a document,
187
00:06:48,400 --> 00:06:50,320
you have a high confidence candidate.
188
00:06:50,320 --> 00:06:51,720
When they disagree, you have a signal
189
00:06:51,720 --> 00:06:53,080
that you need more processing.
190
00:06:53,080 --> 00:06:55,720
But even with this hybrid approach, we still have a problem.
191
00:06:55,720 --> 00:06:57,080
You've improved the may be pile.
192
00:06:57,080 --> 00:07:00,080
You've gone from 78% recall to 91% recall.
193
00:07:00,080 --> 00:07:01,640
You're finding more of the right things.
194
00:07:01,640 --> 00:07:04,800
But you're still handing the LLM a pile of candidates.
195
00:07:04,800 --> 00:07:06,600
And if you've ever looked at a retrieval set,
196
00:07:06,600 --> 00:07:08,920
you know that the top 10 results are often a mess.
197
00:07:08,920 --> 00:07:11,280
You might have the perfect answer at position four.
198
00:07:11,280 --> 00:07:13,280
But at position one, you have a document
199
00:07:13,280 --> 00:07:16,440
that just happens to have the keyword repeated 20 times.
200
00:07:16,440 --> 00:07:18,440
Or you have a document that is mathematically similar,
201
00:07:18,440 --> 00:07:20,520
but completely irrelevant to the current year.
202
00:07:20,520 --> 00:07:22,680
Hybrid search gives you the pieces of the puzzle.
203
00:07:22,680 --> 00:07:24,920
It doesn't necessarily put the puzzle together.
204
00:07:24,920 --> 00:07:27,480
We assume that if we gave the LLM the top five results,
205
00:07:27,480 --> 00:07:29,400
it would be smart enough to pick the right one.
206
00:07:29,400 --> 00:07:32,640
But LLMs are susceptible to distract our documents.
207
00:07:32,640 --> 00:07:34,120
If the first result is a very long,
208
00:07:34,120 --> 00:07:36,520
very confident sounding document that is actually wrong,
209
00:07:36,520 --> 00:07:38,880
the LLM will often prioritize that information
210
00:07:38,880 --> 00:07:41,680
over the correct, shorter document at position three.
211
00:07:41,680 --> 00:07:43,840
This is the lost in the middle phenomenon.
212
00:07:43,840 --> 00:07:45,680
The order of the information determines the quality
213
00:07:45,680 --> 00:07:46,520
of the answer.
214
00:07:46,520 --> 00:07:48,440
So while hybrid search is the baseline,
215
00:07:48,440 --> 00:07:49,640
it is not the final answer.
216
00:07:49,640 --> 00:07:51,120
It's the filtration system.
217
00:07:51,120 --> 00:07:53,680
It gets you from a million documents down to 50.
218
00:07:53,680 --> 00:07:55,680
But 50 documents is still too much noise
219
00:07:55,680 --> 00:07:57,480
for a high stakes business decision.
220
00:07:57,480 --> 00:07:59,640
You are still just looking at a pile of candidates.
221
00:07:59,640 --> 00:08:02,160
You've moved the needle, but you haven't closed the gap.
222
00:08:02,160 --> 00:08:04,400
To actually achieve the 0.9 precision
223
00:08:04,400 --> 00:08:05,960
that health care and finance require,
224
00:08:05,960 --> 00:08:07,600
you can't just stop at retrieval.
225
00:08:07,600 --> 00:08:09,240
You need to add a layer of reasoning
226
00:08:09,240 --> 00:08:11,280
before the data ever touches the LLM.
227
00:08:11,280 --> 00:08:13,920
You need a supervisor who can look at those 50 candidates
228
00:08:13,920 --> 00:08:15,720
and rank them based on actual logic,
229
00:08:15,720 --> 00:08:17,400
not just frequency or coordinates.
230
00:08:17,400 --> 00:08:19,400
Because right now, even with hybrid search,
231
00:08:19,400 --> 00:08:21,080
your co-pilot is still guessing.
232
00:08:21,080 --> 00:08:22,800
It's just making a much more informed guess
233
00:08:22,800 --> 00:08:23,800
than it was before.
234
00:08:23,800 --> 00:08:25,240
We've solved the finding problem.
235
00:08:25,240 --> 00:08:27,080
Now we have to solve the ranking problem.
236
00:08:27,080 --> 00:08:30,120
And that requires a completely different architectural layer.
237
00:08:30,120 --> 00:08:31,440
Even with hybrid search,
238
00:08:31,440 --> 00:08:33,320
you're still just looking at a pile of candidates.
239
00:08:33,320 --> 00:08:35,520
You need a supervisor.
240
00:08:35,520 --> 00:08:36,960
The problem with the hybrid model
241
00:08:36,960 --> 00:08:38,480
is that it lacks an opinion.
242
00:08:38,480 --> 00:08:41,400
It generates a list based on two different scoring systems
243
00:08:41,400 --> 00:08:43,200
that don't really speak the same language.
244
00:08:43,200 --> 00:08:45,080
You're merging coordinates from a vector space
245
00:08:45,080 --> 00:08:47,520
with frequency scores from a keyword index.
246
00:08:47,520 --> 00:08:49,640
The result is a combined top 50 list
247
00:08:49,640 --> 00:08:51,480
that is technically better than before.
248
00:08:51,480 --> 00:08:53,200
But it's still fundamentally unvetted.
249
00:08:53,200 --> 00:08:55,600
It's like a recruitment agency sending you 50 resumes
250
00:08:55,600 --> 00:08:56,600
without actually reading them.
251
00:08:56,600 --> 00:08:58,600
They filtered for keywords in general experience,
252
00:08:58,600 --> 00:09:00,640
but they haven't verified if the person can actually
253
00:09:00,640 --> 00:09:01,400
do the job.
254
00:09:01,400 --> 00:09:04,040
In the rack pipeline, the LLM is your hiring manager.
255
00:09:04,040 --> 00:09:05,720
If you hand that manager 50 resumes,
256
00:09:05,720 --> 00:09:07,080
they're going to get overwhelmed.
257
00:09:07,080 --> 00:09:08,480
They'll glance at the first three,
258
00:09:08,480 --> 00:09:11,480
get distracted by a well-formatted lie and make a bad hire.
259
00:09:11,480 --> 00:09:13,440
To fix this, we need to stop treating search
260
00:09:13,440 --> 00:09:14,680
as a one-step process.
261
00:09:14,680 --> 00:09:16,560
We need to introduce a secondary layer
262
00:09:16,560 --> 00:09:18,080
that acts as a gatekeeper.
263
00:09:18,080 --> 00:09:20,080
Because right now, you aren't providing an answer.
264
00:09:20,080 --> 00:09:21,720
You're providing a homework assignment.
265
00:09:21,720 --> 00:09:23,480
And your AI isn't built to do homework.
266
00:09:23,480 --> 00:09:24,560
It's built to reason.
267
00:09:24,560 --> 00:09:26,240
If you wanted to reason correctly,
268
00:09:26,240 --> 00:09:27,680
you need to give it the right starting point.
269
00:09:27,680 --> 00:09:30,760
You need a supervisor who can look at the top 50 candidates
270
00:09:30,760 --> 00:09:33,400
and decide which one actually holds the truth.
271
00:09:33,400 --> 00:09:35,920
Semantic ranking, the final filter for truth.
272
00:09:35,920 --> 00:09:38,400
This is where we introduce the L2 re-ranca.
273
00:09:38,400 --> 00:09:40,080
In the 2026 architecture,
274
00:09:40,080 --> 00:09:42,320
this is the non-negotiable secondary layer.
275
00:09:42,320 --> 00:09:44,640
It acts as the editor for your search results.
276
00:09:44,640 --> 00:09:47,120
Think about the workflow we've built so far.
277
00:09:47,120 --> 00:09:49,720
First, the hybrid search retrieves a broad set of candidates.
278
00:09:49,720 --> 00:09:50,880
It's fast, it's efficient.
279
00:09:50,880 --> 00:09:53,040
It scans millions of documents in milliseconds,
280
00:09:53,040 --> 00:09:54,720
but it's also shallow.
281
00:09:54,720 --> 00:09:56,320
The L2 re-ranca is the opposite.
282
00:09:56,320 --> 00:09:57,960
It doesn't look at millions of documents.
283
00:09:57,960 --> 00:09:59,560
It only looks at the top 50,
284
00:09:59,560 --> 00:10:01,520
but it looks at them with a level of depth
285
00:10:01,520 --> 00:10:03,880
that the initial search layer could never achieve.
286
00:10:03,880 --> 00:10:06,000
Specifically, in the Microsoft ecosystem,
287
00:10:06,000 --> 00:10:08,120
we're talking about bin-derived models.
288
00:10:08,120 --> 00:10:10,360
These are cross-attention transformers.
289
00:10:10,360 --> 00:10:12,000
Unlike the initial vector search,
290
00:10:12,000 --> 00:10:14,920
which compares a query to a pre-computer document embedding,
291
00:10:14,920 --> 00:10:17,600
the re-ranca looks at the query and the document together.
292
00:10:17,600 --> 00:10:20,640
At the same time, it performs a deep semantic comparison
293
00:10:20,640 --> 00:10:21,600
of the actual text.
294
00:10:21,600 --> 00:10:23,040
It isn't just looking at coordinates
295
00:10:23,040 --> 00:10:24,840
in a high-dimensional space anymore.
296
00:10:24,840 --> 00:10:26,920
It is performing deep reasoning to understand
297
00:10:26,920 --> 00:10:28,960
if the document actually contains the answer
298
00:10:28,960 --> 00:10:30,320
to the specific question asked.
299
00:10:30,320 --> 00:10:33,920
This is where we see the ad search re-ranca score come into play.
300
00:10:33,920 --> 00:10:37,280
This score is different from the similarity scores
301
00:10:37,280 --> 00:10:38,640
you see in the first layer.
302
00:10:38,640 --> 00:10:39,960
A similarity score tells you
303
00:10:39,960 --> 00:10:42,040
this document is mathematically close.
304
00:10:42,040 --> 00:10:43,560
The re-ranca score tells you
305
00:10:43,560 --> 00:10:45,720
this document is relevant to the user's intent.
306
00:10:45,720 --> 00:10:47,920
It moves the goalpost from is this close
307
00:10:47,920 --> 00:10:49,800
to does this answer the question?
308
00:10:49,800 --> 00:10:51,160
This distinction is the only way
309
00:10:51,160 --> 00:10:53,120
to survive in regulated industries.
310
00:10:53,120 --> 00:10:55,280
If you're in finance, healthcare or legal,
311
00:10:55,280 --> 00:10:56,960
0.8 precision is a failure.
312
00:10:56,960 --> 00:10:58,680
You need 0.9 or higher.
313
00:10:58,680 --> 00:11:00,920
You cannot reach that level of accuracy
314
00:11:00,920 --> 00:11:03,000
with a single-stage retrieval process.
315
00:11:03,000 --> 00:11:05,000
The re-ranca is what allows you to move the needle
316
00:11:05,000 --> 00:11:08,080
from mostly right to enterprise grade.
317
00:11:08,080 --> 00:11:10,240
It solves the most common failure mode in rag,
318
00:11:10,240 --> 00:11:11,600
the wrong order problem.
319
00:11:11,600 --> 00:11:13,800
In a standard search, the perfect answer might be sitting
320
00:11:13,800 --> 00:11:14,840
at position eight,
321
00:11:14,840 --> 00:11:16,760
but because it didn't have the right keyword density
322
00:11:16,760 --> 00:11:18,840
or the embedding was slightly fuzzy,
323
00:11:18,840 --> 00:11:19,960
it didn't make it to the top.
324
00:11:19,960 --> 00:11:23,560
The LLM, being lazy, focuses on the first three results.
325
00:11:23,560 --> 00:11:25,280
It misses the truth at position eight
326
00:11:25,280 --> 00:11:26,560
and generates a hallucination
327
00:11:26,560 --> 00:11:28,320
based on the noise at position one.
328
00:11:28,320 --> 00:11:29,800
The re-ranca stops this.
329
00:11:29,800 --> 00:11:31,720
It takes that perfect answer at position eight
330
00:11:31,720 --> 00:11:33,200
and promotes it to position one.
331
00:11:33,200 --> 00:11:35,560
It identifies that while document one has more keywords,
332
00:11:35,560 --> 00:11:37,920
document eight has the actual semantic substance
333
00:11:37,920 --> 00:11:39,800
required to satisfy the query.
334
00:11:39,800 --> 00:11:41,600
This shift from retrieval to ranking
335
00:11:41,600 --> 00:11:43,520
is the most important architectural change
336
00:11:43,520 --> 00:11:44,720
you can make this year.
337
00:11:44,720 --> 00:11:46,800
We have to stop obsessing over how much information
338
00:11:46,800 --> 00:11:47,640
we can find.
339
00:11:47,640 --> 00:11:49,840
We need to start obsessing over the order
340
00:11:49,840 --> 00:11:51,440
in which that information is presented
341
00:11:51,440 --> 00:11:53,320
because the order of information is more important
342
00:11:53,320 --> 00:11:54,560
than the amount of information.
343
00:11:54,560 --> 00:11:56,680
If the right answer is at the bottom of the pile,
344
00:11:56,680 --> 00:11:58,360
it might as well not exist.
345
00:11:58,360 --> 00:12:01,160
The re-ranca ensures the truth is always at the top.
346
00:12:01,160 --> 00:12:03,160
But this isn't just about moving documents around.
347
00:12:03,160 --> 00:12:06,400
The L2 layer also provides semantic captions and highlights.
348
00:12:06,400 --> 00:12:08,960
It identifies the specific verbatim sentences
349
00:12:08,960 --> 00:12:11,440
within the document that are most relevant.
350
00:12:11,440 --> 00:12:13,440
This gives the LLM a cheat sheet.
351
00:12:13,440 --> 00:12:15,920
Instead of asking the model to read a 10 page PDF
352
00:12:15,920 --> 00:12:17,000
and find the needle,
353
00:12:17,000 --> 00:12:19,720
the re-ranca points directly to the needle and says,
354
00:12:19,720 --> 00:12:21,920
"Read these three sentences specifically."
355
00:12:21,920 --> 00:12:24,680
This reduces the cognitive load on the LLM.
356
00:12:24,680 --> 00:12:27,000
It minimizes the risk of the model getting distracted
357
00:12:27,000 --> 00:12:29,080
by a relevant context elsewhere in the document.
358
00:12:29,080 --> 00:12:30,800
It's the difference between giving someone a book
359
00:12:30,800 --> 00:12:32,600
and giving them a highlighted paragraph.
360
00:12:32,600 --> 00:12:35,840
Which one do you think leads to a faster, more accurate answer?
361
00:12:35,840 --> 00:12:38,360
In 2026, this is how we solve the trust gap.
362
00:12:38,360 --> 00:12:42,040
Users stop trusting co-pilot when it gives them three sort of answers
363
00:12:42,040 --> 00:12:43,880
and misses the one definitely answer.
364
00:12:43,880 --> 00:12:46,320
The re-ranca is the tool that ensures the definitely answer
365
00:12:46,320 --> 00:12:48,160
is always the first thing the user sees.
366
00:12:48,160 --> 00:12:50,080
It acts as the final filter for truth.
367
00:12:50,080 --> 00:12:51,720
It bridges the gap between raw data
368
00:12:51,720 --> 00:12:53,400
and actionable intelligence.
369
00:12:53,400 --> 00:12:55,760
However, we have to be honest about the trade-offs.
370
00:12:55,760 --> 00:12:57,960
This level of precision is not a free lunch.
371
00:12:57,960 --> 00:12:59,960
When you move from a simple math-based search
372
00:12:59,960 --> 00:13:01,520
to a reasoning-based re-ranca,
373
00:13:01,520 --> 00:13:03,040
the economics of your system change.
374
00:13:03,040 --> 00:13:05,520
You are adding compute, you are adding latency.
375
00:13:05,520 --> 00:13:07,640
And in a cloud-hosted environment like Azure,
376
00:13:07,640 --> 00:13:09,240
you are adding direct costs.
377
00:13:09,240 --> 00:13:11,080
If you don't manage this layer correctly,
378
00:13:11,080 --> 00:13:12,960
the precision you gain will be erased
379
00:13:12,960 --> 00:13:15,680
by the infrastructure bill you receive at the end of the month.
380
00:13:15,680 --> 00:13:17,880
We need to understand the economics of accuracy.
381
00:13:17,880 --> 00:13:19,560
Because in the enterprise, a perfect answer
382
00:13:19,560 --> 00:13:22,320
that costs $10 to generate is often less valuable
383
00:13:22,320 --> 00:13:25,040
than a good enough answer that costs $10.
384
00:13:25,040 --> 00:13:27,280
The challenge of 2026 is balancing the need
385
00:13:27,280 --> 00:13:30,960
for 0.9 precision with the reality of a finite budget.
386
00:13:30,960 --> 00:13:32,160
You need the supervisor,
387
00:13:32,160 --> 00:13:33,800
but you also need to make sure the supervisor
388
00:13:33,800 --> 00:13:36,080
isn't the most expensive person in the building.
389
00:13:36,080 --> 00:13:37,920
But this precision comes with a cost.
390
00:13:37,920 --> 00:13:39,720
And if you don't manage the infrastructure,
391
00:13:39,720 --> 00:13:41,680
the ROI disappears.
392
00:13:41,680 --> 00:13:44,040
The shift toward a multi-stage retrieval architecture
393
00:13:44,040 --> 00:13:46,120
creates a fundamental tension between the quality
394
00:13:46,120 --> 00:13:48,400
of the answer and the sustainability of the budget.
395
00:13:48,400 --> 00:13:50,480
We've reached a point where the technical possibility
396
00:13:50,480 --> 00:13:52,840
of 0.9 precision is real.
397
00:13:52,840 --> 00:13:55,040
But the financial feasibility is often ignored.
398
00:13:55,040 --> 00:13:56,200
In the early days of RAAG,
399
00:13:56,200 --> 00:13:58,480
we were focused on proving that the concept worked.
400
00:13:58,480 --> 00:14:00,040
We didn't care about the cost per query
401
00:14:00,040 --> 00:14:01,480
because the volumes were low.
402
00:14:01,480 --> 00:14:05,360
But as you scale from 10 users to 10,000, the math changes.
403
00:14:05,360 --> 00:14:06,720
The secondary layer of reasoning
404
00:14:06,720 --> 00:14:08,400
that makes the system trustworthy
405
00:14:08,400 --> 00:14:11,000
is also the layer that can make it prohibitively expensive.
406
00:14:11,000 --> 00:14:13,120
Because in the enterprise, accuracy is a luxury good.
407
00:14:13,120 --> 00:14:14,760
And if you haven't designed your infrastructure
408
00:14:14,760 --> 00:14:16,520
to handle the weight of that luxury,
409
00:14:16,520 --> 00:14:18,920
your project will consume its own ROI
410
00:14:18,920 --> 00:14:23,680
before it ever delivers a single dollar of measurable value.
411
00:14:23,680 --> 00:14:26,560
The economics of accuracy, performance versus cost.
412
00:14:26,560 --> 00:14:29,560
The reality of the standard tier in Azure AI search
413
00:14:29,560 --> 00:14:31,920
is that semantic ranking is a pay to play game.
414
00:14:31,920 --> 00:14:33,160
You cannot simply toggle a switch
415
00:14:33,160 --> 00:14:35,320
and expect your existing budget to hold.
416
00:14:35,320 --> 00:14:38,480
When you enable the ad search, re-rank a score functionality,
417
00:14:38,480 --> 00:14:40,400
you are moving away from the fixed cost world
418
00:14:40,400 --> 00:14:42,640
of basic search units and entering a world
419
00:14:42,640 --> 00:14:44,200
of variable query time billing.
420
00:14:44,200 --> 00:14:46,440
Let's look at the numbers for a moderate query volume.
421
00:14:46,440 --> 00:14:49,240
Say 50,000 searches per month on a 20 gigabyte data set,
422
00:14:49,240 --> 00:14:50,720
you are looking at a monthly overhead
423
00:14:50,720 --> 00:14:52,680
between $308 hundred dollars.
424
00:14:52,680 --> 00:14:54,800
That might sound manageable for a single department.
425
00:14:54,800 --> 00:14:57,400
But when you consider that this is just the search layer.
426
00:14:57,400 --> 00:14:59,360
And you still have to pay for the LLM tokens
427
00:14:59,360 --> 00:15:00,800
and the embedding generation.
428
00:15:00,800 --> 00:15:03,160
The total cost of ownership begins to spike.
429
00:15:03,160 --> 00:15:05,240
We've seen organizations launch a co-pilot pilot
430
00:15:05,240 --> 00:15:07,640
see massive success in user satisfaction
431
00:15:07,640 --> 00:15:09,280
and then immediately pull the plug
432
00:15:09,280 --> 00:15:11,480
when the first full-scale invoice arrives.
433
00:15:11,480 --> 00:15:12,960
They were so focused on the performance
434
00:15:12,960 --> 00:15:15,440
that they forgot to check the price tag of that performance.
435
00:15:15,440 --> 00:15:17,440
This is the primary reason why RAC projects
436
00:15:17,440 --> 00:15:19,720
die in the transition from lab to production.
437
00:15:19,720 --> 00:15:22,320
The cost of being right is higher than the cost of being wrong.
438
00:15:22,320 --> 00:15:23,520
So how do we solve this?
439
00:15:23,520 --> 00:15:25,480
How do we keep the precision without bankrupting
440
00:15:25,480 --> 00:15:28,360
the IT department, the Anselis and semantic caching?
441
00:15:28,360 --> 00:15:32,400
In 2026, semantic caching is the ROI savior for the enterprise.
442
00:15:32,400 --> 00:15:34,160
Here's the problem we're solving.
443
00:15:34,160 --> 00:15:36,120
Employees tend to ask the same questions
444
00:15:36,120 --> 00:15:37,640
in slightly different ways.
445
00:15:37,640 --> 00:15:39,320
What's the holiday policy?
446
00:15:39,320 --> 00:15:41,520
Can you show me the rules for time off?
447
00:15:41,520 --> 00:15:43,280
How many days of vacation do I get?
448
00:15:43,280 --> 00:15:44,480
In a standard RAC pipeline,
449
00:15:44,480 --> 00:15:46,600
each of those questions triggers a full retrieval,
450
00:15:46,600 --> 00:15:48,760
a semantic rerank and an LLM call.
451
00:15:48,760 --> 00:15:50,640
You are paying for the same answer three times.
452
00:15:50,640 --> 00:15:52,120
Semantic caching stops that waste.
453
00:15:52,120 --> 00:15:54,960
It uses a lightweight embedding model to identify
454
00:15:54,960 --> 00:15:57,200
that those three questions share the same intent.
455
00:15:57,200 --> 00:15:59,560
Instead of going back to the expensive reasoning engine,
456
00:15:59,560 --> 00:16:01,160
the system pulls the verified answer
457
00:16:01,160 --> 00:16:02,440
from a high-speed cache.
458
00:16:02,440 --> 00:16:05,680
This can reduce your LLM calls by 60% to 80%.
459
00:16:05,680 --> 00:16:08,440
And the user experience transformation is even more dramatic.
460
00:16:08,440 --> 00:16:11,080
You go from a three-second wait for a live GPT-4 inference
461
00:16:11,080 --> 00:16:12,960
to a sub-50mila's cache hit.
462
00:16:12,960 --> 00:16:14,880
That is a 250x speed improvement.
463
00:16:14,880 --> 00:16:17,280
Suddenly, the copilot feels instant.
464
00:16:17,280 --> 00:16:19,960
It moves from being a slow tool that people tolerate
465
00:16:19,960 --> 00:16:23,120
to a responsive assistant that people actually enjoy using.
466
00:16:23,120 --> 00:16:24,640
But caching is only half the battle.
467
00:16:24,640 --> 00:16:26,600
The other half is selective enablement.
468
00:16:26,600 --> 00:16:28,680
One of the biggest mistakes architects make
469
00:16:28,680 --> 00:16:31,600
is applying semantic ranking to every single query.
470
00:16:31,600 --> 00:16:33,520
You don't need a deep reasoning transformer
471
00:16:33,520 --> 00:16:37,160
to find a document title 2025 expense report template.
472
00:16:37,160 --> 00:16:39,520
A basic keyword matches more than enough for that.
473
00:16:39,520 --> 00:16:41,960
The strategy for 2026 is to keep the simple hits
474
00:16:41,960 --> 00:16:42,800
on the cheap layer.
475
00:16:42,800 --> 00:16:45,440
You should only trigger the L2 re-ranca on complex,
476
00:16:45,440 --> 00:16:48,080
natural language queries where the intent is ambiguous.
477
00:16:48,080 --> 00:16:50,920
By implementing a logic gate at the front of your pipeline,
478
00:16:50,920 --> 00:16:52,920
you can reserve your budget for the queries
479
00:16:52,920 --> 00:16:54,720
that actually need the extra precision.
480
00:16:54,720 --> 00:16:56,240
Think of it like a triage system.
481
00:16:56,240 --> 00:16:59,160
The cheap layer handles the 70% of routine requests.
482
00:16:59,160 --> 00:17:00,920
The expensive semantic layer handles
483
00:17:00,920 --> 00:17:03,440
the 30% that actually drive business value.
484
00:17:03,440 --> 00:17:04,880
This is how you balance the budget.
485
00:17:04,880 --> 00:17:06,240
And you make sure the cost of the search
486
00:17:06,240 --> 00:17:08,160
doesn't exceed the value of the answer.
487
00:17:08,160 --> 00:17:10,560
If a query is worth 10 cents of productivity,
488
00:17:10,560 --> 00:17:12,520
don't spend a dollar of compute to solve it.
489
00:17:12,520 --> 00:17:15,160
We also have to consider the tiering of the data itself.
490
00:17:15,160 --> 00:17:17,600
Not all documents require 0.9 precision.
491
00:17:17,600 --> 00:17:19,160
Your internal cafeteria menu doesn't need
492
00:17:19,160 --> 00:17:20,600
a Bing derived re-ranca.
493
00:17:20,600 --> 00:17:22,160
But your regulatory compliance documents
494
00:17:22,160 --> 00:17:24,520
do by partitioning your search indexes
495
00:17:24,520 --> 00:17:26,920
and applying different ranking strategies to each.
496
00:17:26,920 --> 00:17:29,640
You can optimize your spend based on the criticality
497
00:17:29,640 --> 00:17:31,280
of the information.
498
00:17:31,280 --> 00:17:33,320
This is what we call value-based retrieval.
499
00:17:33,320 --> 00:17:36,640
It's the realization that accuracy is not a binary choice.
500
00:17:36,640 --> 00:17:38,000
It's a sliding scale.
501
00:17:38,000 --> 00:17:40,240
And as an architect, your job is to move that slider
502
00:17:40,240 --> 00:17:42,600
based on the specific needs of the business unit.
503
00:17:42,600 --> 00:17:45,360
The goal isn't to build the most accurate system possible.
504
00:17:45,360 --> 00:17:47,280
The goal is to build the most accurate system
505
00:17:47,280 --> 00:17:49,320
that the business can actually afford to run.
506
00:17:49,320 --> 00:17:51,880
Because a perfect AI that is too expensive to use
507
00:17:51,880 --> 00:17:53,920
is just a very sophisticated paperweight.
508
00:17:53,920 --> 00:17:57,320
In 2026, the winners won't be the ones with the highest benchmarks.
509
00:17:57,320 --> 00:17:58,640
They will be the ones who figured out
510
00:17:58,640 --> 00:18:01,920
how to deliver 0.85 precision at a cost
511
00:18:01,920 --> 00:18:03,680
that scales linearly with their growth.
512
00:18:03,680 --> 00:18:05,560
They are the ones who treated the infrastructure
513
00:18:05,560 --> 00:18:07,720
as a constraint, not an afterthought.
514
00:18:07,720 --> 00:18:10,520
Managing the cost is the technical side of the equation.
515
00:18:10,520 --> 00:18:12,120
But even if you get the economics right,
516
00:18:12,120 --> 00:18:13,520
you still have a human problem.
517
00:18:13,520 --> 00:18:16,240
You have to address the gap between the licenses you've bought
518
00:18:16,240 --> 00:18:18,640
and the actual trust your users have in the system.
519
00:18:18,640 --> 00:18:20,040
Because if they don't trust the answer,
520
00:18:20,040 --> 00:18:21,720
it doesn't matter how much it costs to generate.
521
00:18:21,720 --> 00:18:23,680
They'll just go back to searching the old way.
522
00:18:23,680 --> 00:18:25,800
And that brings us to the governance gap.
523
00:18:25,800 --> 00:18:28,120
Because trust isn't just about technical accuracy.
524
00:18:28,120 --> 00:18:30,200
It's about the framework that surrounds that accuracy.
525
00:18:30,200 --> 00:18:32,840
It's about knowing that the AI isn't just right,
526
00:18:32,840 --> 00:18:35,400
but that it's allowed to be right in the first place.
527
00:18:35,400 --> 00:18:37,200
Managing the cost is the technical side,
528
00:18:37,200 --> 00:18:40,080
but the executive side is about the governance gap.
529
00:18:40,080 --> 00:18:43,280
Optimizing your infrastructure only solves part of the equation.
530
00:18:43,280 --> 00:18:45,280
You can build the most cost-efficient precision engine
531
00:18:45,280 --> 00:18:47,080
in the world, but if your leadership team
532
00:18:47,080 --> 00:18:48,840
is terrified of what it might surface,
533
00:18:48,840 --> 00:18:50,960
the project will never leave the sandbox.
534
00:18:50,960 --> 00:18:52,800
We have reached a point where the bottleneck isn't
535
00:18:52,800 --> 00:18:55,520
the compute budget or the latency of the re-renker.
536
00:18:55,520 --> 00:18:58,360
The real friction is the gap between the licenses you've
537
00:18:58,360 --> 00:19:01,800
assigned and the actual authority the AI has to operate.
538
00:19:01,800 --> 00:19:04,760
The governance gap, why policies are failing usage?
539
00:19:04,760 --> 00:19:08,000
We currently have 50 million paid seats in the ecosystem.
540
00:19:08,000 --> 00:19:09,640
Yet, the workplace conversion rate
541
00:19:09,640 --> 00:19:12,360
is stuck at a staggering 35%.
542
00:19:12,360 --> 00:19:14,640
This means two out of every three licensed users
543
00:19:14,640 --> 00:19:16,160
are essentially ignoring the tool.
544
00:19:16,160 --> 00:19:18,520
They stop using it after the third hallucination.
545
00:19:18,520 --> 00:19:21,560
Trust is fragile, and poor retrieval destroys it faster
546
00:19:21,560 --> 00:19:24,360
than any training session can build it.
547
00:19:24,360 --> 00:19:26,040
Governance isn't just a document.
548
00:19:26,040 --> 00:19:28,040
It's a technical control.
549
00:19:28,040 --> 00:19:30,960
Without it, your RAC project dies at week 12.
550
00:19:30,960 --> 00:19:33,160
So what does the new model look like in practice?
551
00:19:33,160 --> 00:19:35,400
It's a move toward governed agents.
552
00:19:35,400 --> 00:19:37,680
The era of the chat box is ending.
553
00:19:37,680 --> 00:19:40,440
We are moving away from a world where you ask a question
554
00:19:40,440 --> 00:19:42,240
and hope the math finds a document.
555
00:19:42,240 --> 00:19:43,760
The new model is about delegation.
556
00:19:43,760 --> 00:19:45,920
It's about moving from a system that merely retrieves
557
00:19:45,920 --> 00:19:49,000
to one that actually reasons about the search process itself.
558
00:19:49,000 --> 00:19:51,560
We are entering the age of the governed agent,
559
00:19:51,560 --> 00:19:53,600
a system that doesn't just look for data,
560
00:19:53,600 --> 00:19:55,240
but understands the rules of the house
561
00:19:55,240 --> 00:19:57,240
before it even starts the engine.
562
00:19:57,240 --> 00:20:00,480
The 2026 road map, from retrieval to reasoning.
563
00:20:00,480 --> 00:20:03,000
If you want to stay relevant in the next 24 months,
564
00:20:03,000 --> 00:20:05,120
your road map has to shift toward a genetic rag.
565
00:20:05,120 --> 00:20:06,280
This is the next frontier.
566
00:20:06,280 --> 00:20:08,320
In a standard setup, the system takes your query
567
00:20:08,320 --> 00:20:09,680
and runs a single search.
568
00:20:09,680 --> 00:20:12,120
In an agente setup, the AI plans the search.
569
00:20:12,120 --> 00:20:13,680
It looks at your request and decides
570
00:20:13,680 --> 00:20:16,960
if it needs to hit the vector store, query a SQL database,
571
00:20:16,960 --> 00:20:18,680
or perhaps check a real-time API.
572
00:20:18,680 --> 00:20:21,000
It reasons through the steps required to find the truth.
573
00:20:21,000 --> 00:20:23,280
This is where GraphRag becomes the gold standard.
574
00:20:23,280 --> 00:20:26,800
For high stakes environments, where you need 99% accuracy,
575
00:20:26,800 --> 00:20:28,920
you can't rely on flat document chunks.
576
00:20:28,920 --> 00:20:30,920
You need a knowledge graph that maps the relationships
577
00:20:30,920 --> 00:20:31,920
between entities.
578
00:20:31,920 --> 00:20:33,920
People, projects, and policies.
579
00:20:33,920 --> 00:20:35,360
This allows the AI to understand
580
00:20:35,360 --> 00:20:38,040
that when you ask about the lead engineers' budget,
581
00:20:38,040 --> 00:20:40,560
it needs to find the person, then the project they lead,
582
00:20:40,560 --> 00:20:42,240
and then the specific financial ledger
583
00:20:42,240 --> 00:20:43,760
associated with that project.
584
00:20:43,760 --> 00:20:45,200
It's a multi-hop reasoning chain
585
00:20:45,200 --> 00:20:47,720
that flat vector search simply cannot perform.
586
00:20:47,720 --> 00:20:48,920
But here is the hard truth.
587
00:20:48,920 --> 00:20:52,720
Your AI is gated by your metadata, not your license count.
588
00:20:52,720 --> 00:20:54,520
If your SharePoint sites are a graveyard
589
00:20:54,520 --> 00:20:58,480
of document one, DocX, and Final V2, really Final.PDF,
590
00:20:58,480 --> 00:21:00,760
no amount of agente reasoning will save you.
591
00:21:00,760 --> 00:21:02,760
Preparing your data foundation is the only way
592
00:21:02,760 --> 00:21:04,920
to avoid the competitive lag that is coming.
593
00:21:04,920 --> 00:21:07,880
Organizations that wait to fix their retrieval layer
594
00:21:07,880 --> 00:21:11,240
will find themselves stuck with a 35% adoption rate
595
00:21:11,240 --> 00:21:14,360
while their competitors are automating entire workflows.
596
00:21:14,360 --> 00:21:16,600
We are moving from vector search as a tool
597
00:21:16,600 --> 00:21:20,080
to semantic strategy as a core business competency.
598
00:21:20,080 --> 00:21:22,600
Your transformation starts with a retrieval audit.
599
00:21:22,600 --> 00:21:24,920
Stop measuring how fast the AI responds
600
00:21:24,920 --> 00:21:27,040
and start measuring how often it's actually right.
601
00:21:27,040 --> 00:21:30,400
Identify the top 10% of your most complex use cases.
602
00:21:30,400 --> 00:21:33,360
The ones where accuracy is a requirement, not a suggestion,
603
00:21:33,360 --> 00:21:36,440
and implement the L2 re-ranker on those pipelines today.
604
00:21:36,440 --> 00:21:38,280
If this shift in the model changed how you think
605
00:21:38,280 --> 00:21:39,880
about your architecture, follow me,
606
00:21:39,880 --> 00:21:42,280
MirkoPeters, on LinkedIn for more deep dives.
607
00:21:42,280 --> 00:21:44,360
If this helped you diagnose why your RAC project
608
00:21:44,360 --> 00:21:46,480
is currently failing, leave a review.
609
00:21:46,480 --> 00:21:48,320
It helps this podcast reach the architects
610
00:21:48,320 --> 00:21:50,760
who are still struggling in the top K-Trap.
611
00:21:50,760 --> 00:21:52,600
Your next step is to check out our deep dive
612
00:21:52,600 --> 00:21:55,080
on agente workflows to see exactly where this precision
613
00:21:55,080 --> 00:21:56,160
is headed next.

Founder of m365.fm, m365.show and m365con.net
Mirko Peters is a Microsoft 365 expert, content creator, and founder of m365.fm, a platform dedicated to sharing practical insights on modern workplace technologies. His work focuses on Microsoft 365 governance, security, collaboration, and real-world implementation strategies.
Through his podcast and written content, Mirko provides hands-on guidance for IT professionals, architects, and business leaders navigating the complexities of Microsoft 365. He is known for translating complex topics into clear, actionable advice, often highlighting common mistakes and overlooked risks in real-world environments.
With a strong emphasis on community contribution and knowledge sharing, Mirko is actively building a platform that connects experts, shares experiences, and helps organizations get the most out of their Microsoft 365 investments.