
Govern Data in a Microsoft Fabric Lakehouse: Architecture Without Losing Sleep

You know that awkward moment when someone in a meeting asks, “Can we prove where this number came from?” and the room goes quiet? I’ve watched that silence stretch in companies that had “all the data” but none of the receipts. Lakehouses promise one platform for everything—structured tables, messy files, real-time feeds, ML features—but the promise only holds if you can govern it without handcuffing your teams. This post borrows heavily from the October 2024 Stallion Journal study on “Data Governance in Lakehouse” (Shah & Jain) and then adds the human layer: the shortcuts you’re tempted to take, the politics you’ll bump into, and the simple habits that keep you out of audit-induced panic.
8 Surprising Facts About Govern in a Microsoft Fabric Lakehouse
- Unified governance across artifacts: Fabric’s governance applies uniformly to lakehouse tables, files, notebooks, pipelines and dashboards, enabling centralized policies that span both data and analytics artifacts.
- Automatic lineage capture: Lineage is captured automatically for many operations (ingest, transformations, notebooks, and dashboards), giving near-real-time visibility into data provenance without extra instrumentation.
- Row-level and column-level security integration: Lakehouse supports fine-grained access controls (row- and column-level) enforced at query time, so governed access travels with the data regardless of consumption engine.
- Built-in data classification and sensitivity labels: Fabric surfaces data classification (sensitive info types) and integrates with Microsoft Purview sensitivity labels so governance can use discovered classifications for policy enforcement.
- Policy-as-code for lifecycle controls: Governance policies (retention, quality gates, encryption, allowed compute) can be expressed and applied programmatically, enabling automated enforcement across the lakehouse lifecycle.
- Seamless tenant and workspace isolation: Fabric’s governance model supports multi-workspace isolation and tenant-aware policies so you can restrict sharing and data movement between projects while still enabling governed collaboration.
- Auditable mutation and access logs: All governance-relevant operations (data reads/writes, policy changes, role assignments) are auditable, producing logs that integrate with Microsoft Sentinel and SIEMs for compliance monitoring.
- Governance-enabled data contracts: Fabric allows creation of data contracts and schemas with enforced compatibility checks—so consumers get stable, governed interfaces to lakehouse data and producers can evolve safely.
1) The “quiet meeting” problem: why lakehouses need governance
You’re in a leadership review. A KPI flashes on the screen—revenue retention, patient wait time, churn risk. Someone asks, “Where did this number come from?” The room goes quiet. You can’t trace the dataset, the transformation, or who changed the logic last week. In that moment, you don’t have an analytics problem—you have a data trust problem.
Lakehouse in plain language: one roof, two promises
A lakehouse is a practical blend: data lake flexibility (store anything, fast) plus data warehouse reliability (consistent tables, strong performance). Under one roof, you can manage structured and unstructured data, run real-time analytics, and support machine learning workloads. That “all-in-one” value is also why your lakehouse architecture strategy must include governance from day one.
Why lakehouses intensify lakehouse data governance needs
Lakehouses move quickly: streaming feeds, frequent model retraining, and many teams shipping dashboards at once. That speed multiplies risk. Mixed data types and many tools make it easier to lose track of definitions, permissions, and lineage. When you can’t explain a metric, stakeholders stop trusting the dashboard—even if the number is correct.
- Real-time data increases the chance of inconsistent snapshots and “moving target” KPIs.
- ML pipelines add new assets to govern: features, training sets, model outputs, and drift signals.
- More users (analysts, data scientists, product teams) means more access paths—and more ways to break policy.
Governance isn’t paperwork—it’s how you keep shipping safely
The peer-reviewed Stallion Journal study “Data Governance in Lakehouse” (Samarth Shah, University at Albany; Shubham Jain, IIT Bombay) published on 22-10-2024 in Volume 3, Issue 5 (pp. 126–145, ISSN 2583-3340; DOI: https://doi.org/10.55544/sjmars.3.5.12) frames governance as both a strategic necessity and an operational must-have. The message is simple: governance protects you on compliance (GDPR, HIPAA, CCPA), reduces risk, and sustains data quality and stakeholder trust.
Samarth Shah: “In a lakehouse, speed without governance isn’t agility—it’s just faster confusion.”
In practice, lakehouse data governance means you can answer “what is this KPI?” with evidence: metadata, catalog entries, access controls (like RBAC), audit trails, and lineage. It’s not red tape. It’s the system that lets you deliver analytics fast—without breaking laws or breaking trust.
| Metadata item | Value |
|---|---|
| Publication date | 22-10-2024 |
| Journal issue | Volume 3, Issue 5 (Oct 2024) |
| Pages | 126–145 |
| ISSN | 2583-3340 |

2) What “good governance” looks like when your data is everywhere
In a lakehouse, your data is not “in one place.” It’s across tables, files, streams, and ML features—often on platforms like AWS, Snowflake, or Databricks. Good governance is how you keep it usable and safe without slowing teams down. Think of it as guardrails, not gates: you enable real-time analytics while meeting GDPR, HIPAA, and CCPA expectations.
The 6 building blocks you’ll actually implement
- Metadata-driven governance: define owners, sensitivity, retention, and quality rules in metadata so controls scale with volume and change.
- Data catalog best practices: one searchable place for definitions, tags, and trusted datasets—so people stop guessing.
- RBAC access control: roles map to job needs (analyst, engineer, clinician), not ad-hoc permissions.
- Data lineage tracking: show where data came from, how it changed, and what it feeds.
- Audit trails: who accessed what, when, and what they did—critical for investigations and audits.
- Policy enforcement: automated checks (masking, retention, approvals) that run by default, not by request.
Documented vs. enforced governance (only one prevents incidents)
Documented governance is a wiki page that says “PII must be masked.” Enforced governance is when your lakehouse automatically masks PII based on metadata tags, blocks risky exports, and logs access in audit trails. The research behind modern lakehouse governance shows that automation and metadata reduce manual enforcement time and errors—because the platform applies rules consistently.
Unified governance when you juggle tables, files, streams, and features
You need one control plane that works across batch tables, object-store files, Kafka-like streams, and ML feature sets. When governance is unified, the same RBAC access control, tags, and policies follow the data—so your dashboards, notebooks, and models stay aligned and compliant.
Small tangent: how “one shared dataset” becomes 12 versions
Without data lineage tracking, a “customer” dataset gets copied into customer_v2, customer_clean, customer_final, and “final_final.” Soon, teams argue over numbers because nobody can prove which version fed which report.
Shubham Jain: “Lineage is the difference between ‘I think’ and ‘I can prove it’ when someone challenges your numbers.”
5-minute self-checklist
- Can you find the owner and sensitivity tag for your top 10 datasets in the catalog?
- Do roles (not individuals) control access via RBAC?
- Can you trace a KPI back to sources with lineage in under 2 minutes?
- Do audit trails answer “who viewed/exported this” today?
- Are policies enforced automatically (masking, retention, approvals), not manually?
Each control ties to outcomes: fewer access incidents (RBAC + policies), faster audits (audit trails + catalog), and cleaner analytics (metadata + lineage).
3) The numbers that make governance feel less like ‘overhead’
If governance sounds like “extra process,” the paper’s results help you reframe it as measurable operational gain. When you apply metadata-driven governance with automation and ML in a lakehouse, you are not just “adding controls”—you are buying back time, improving trust in data, and reducing compliance risk in ways a CFO can track.
Metadata-driven governance: ROI you can put on a slide
The study reports three headline outcomes when teams lean on strong metadata, cataloging, lineage, and access controls:
- Up to 40% governance efficiency improvement
- 35% increase in data quality
- 92% GDPR HIPAA compliance achievement rates (GDPR/HIPAA)
In practical terms, that 40% efficiency gain often means fewer manual reviews, fewer “who owns this dataset?” loops, and faster approvals for access and sharing. Your backlog shrinks because routine checks move from people to systems, and your incident queue drops because fewer issues reach production.
Automated policy enforcement: the before/after that changes the conversation
The clearest “overhead vs. payoff” proof is the shift from manual controls to automated policy enforcement:
- Policy enforcement time: 72% → 28%
- Error rate: 45% → 15%
That is not a small optimization. It is the difference between governance being a gate and governance being a guardrail. You spend less time chasing exceptions and more time enabling safe self-service.
“Unified governance only sticks when the workflow is easier than the workaround.” —Taylor, Singh, & Green (2021)
Adoption reality: strong for technical users, harder for everyone else
Usability scores were high among data scientists, business analysts, and IT administrators (4.2–4.7/5). But the paper also flags a common gap: non-technical users need simpler interfaces, clearer definitions, and guided workflows. If you want the numbers above, you must budget for enablement, not just tooling.
Key metrics at a glance
| Metric | Result |
|---|---|
| Governance efficiency improvement | Up to 40% |
| Data quality increase | 35% |
| GDPR HIPAA compliance rate | 92% |
| Policy enforcement time | 72% (manual) vs 28% (automated) |
| Error rate | 45% (manual) vs 15% (automated) |
| Usability rating | 4.2–4.7 out of 5 |
| Processing time reduction | 25% |
4) Tools, prototypes, and the messy truth of implementation
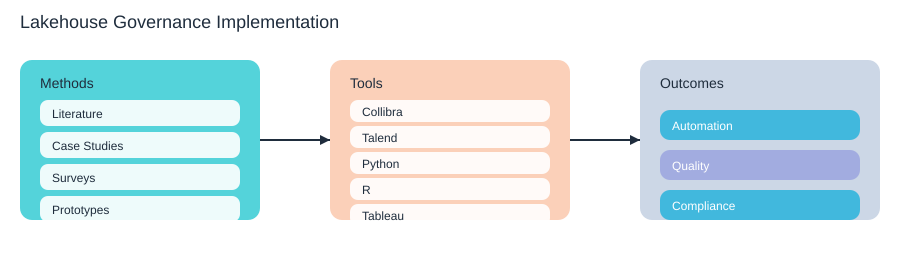
What the research did (in plain terms)
The Stallion Journal study didn’t treat governance like a slide deck problem. It used four methods you can recognize from real work: it read the literature (systematic reviews), looked at industry case studies, surveyed stakeholders, and then tested prototypes. That last part matters, because lakehouse governance breaks in the gaps between policy and pipelines—especially when your data arrives fast, changes often, and comes from many teams.
Prototype stack: what they actually tried
In experimentation, the study used Collibra and Talend for governance and integration patterns, plus analytics tools (Python, R, Tableau) to validate usability and outcomes. You can mirror this approach whether you’re doing Databricks governance, a Snowflake lakehouse setup, or broader cloud-native data governance with Kubernetes, Docker, Kafka, Postgres, PySpark, and Elasticsearch in the mix.
A rollout path you can copy (and keep sane)
Implementation success depends on tool-supported governance and your capacity to handle velocity, complexity, and resourcing constraints. A practical sequence is:
- Start with catalog + RBAC: adopt data catalog best practices (clear ownership, business terms, and “golden” datasets). Then map access using RBAC.
- Add lineage: capture upstream/downstream impact so changes don’t surprise analysts or auditors.
- Automate enforcement: move from manual approvals to policy-as-code where possible, with audit trails.
Harris & Nguyen (2020): “RBAC is simple on paper; it gets real the day you map it to teams, not job titles.”
Your daily enemy: velocity and inconsistent streams
High-velocity feeds (think Kafka-style streams) create “schema drift,” late events, and duplicate records. That’s where governance feels messy: your catalog says a field is required, but the stream drops it; your quality rules expect one timestamp, but producers send three. The study flags this as a recurring blocker, especially when teams are understaffed.
Tool sprawl: when systems disagree
Watch for the classic split-brain problem: your catalog shows Dataset A is “restricted,” but IAM groups still allow broad access. Or your Databricks governance policies don’t match what’s configured in cloud IAM. Treat “one source of truth” as a design goal, not a slogan.
| Decision lens | Keep it simple |
|---|---|
| Buy vs build | Buy for catalog/workflows; build only thin connectors and checks. |
| Avoid a governance maze | One catalog, one policy model, minimal custom roles, automated audits. |
5) The top governance pain points (and how you triage them)
If you feel like governance is harder than it “should” be, you’re not alone. In the research synthesis, 78% of organizations cite the metadata management challenge as the primary pain point. That stat should make you feel seen—because in a lakehouse, everything moves fast, and metadata is the map you’re trying to update while the roads are still being built.
Why metadata breaks first (and keeps breaking)
Metadata is hard because:
- Definitions drift: “Active customer” means one thing to Finance and another to Growth.
- Ownership is fuzzy: nobody is sure who approves a new field, a new table, or a new retention rule.
- Pipelines change weekly: new sources, new joins, new ML features—your catalog and tags fall behind.
And yet, when you invest in governance, you get measurable returns: 88% report improved data quality governance, and 81% report better lakehouse security governance. That’s the payoff for doing the unglamorous work.
Governance triage: fix the right things in the right order
- Metadata + ownership first: define critical data elements, assign a data owner and steward, and standardize business terms in your catalog.
- Access control next: implement RBAC with least privilege, plus clear approval paths for exceptions.
- Lineage and audit trails: track where data came from, how it changed, and who touched it—this is where GDPR/HIPAA/CCPA questions get answered fast.
- Automation last (but steadily): automate policy checks, tagging, and anomaly detection so enforcement doesn’t depend on heroics.
What breaks when HIPAA meets CCPA?
Picture a lakehouse where a HIPAA-regulated healthcare dataset (patient encounters) is joined with a CCPA-covered marketing dataset (web behavior). What breaks first is usually classification and consent: PHI tags are missing, consent flags don’t propagate through joins, and a downstream dashboard exposes more than intended. Without lineage, you can’t prove where the data went; without RBAC, you can’t stop broad access; without audit trails and identity management, you can’t show accountability.
“The real challenge is not making AI work, but making it work responsibly within the systems you already have.”
— Dr. Fei-Fei Li
A simple ritual that keeps you sane: the monthly governance retro
Run a 45-minute monthly retro with IT, security, and business owners. Review: top 3 metadata gaps, top 3 access exceptions, one lineage failure, and one automation win. Log actions in a shared tracker and assign a single owner per item.
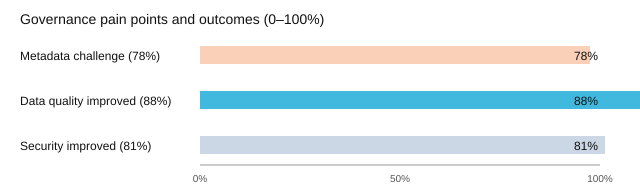
6) Compliance without paranoia: GDPR, HIPAA, CCPA in the lakehouse
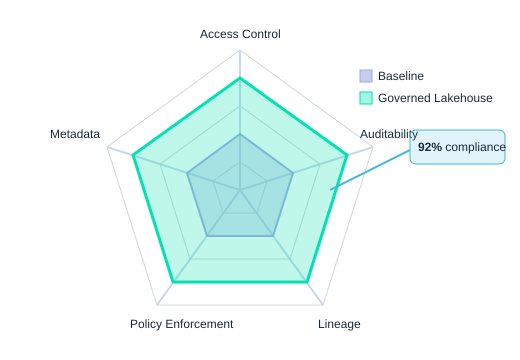
In a lakehouse, treat compliance as a design constraint, not a last-minute scramble. When you build controls into ingestion, storage, and access from day one, GDPR HIPAA compliance and CCPA data governance stop feeling like fire drills and start feeling like normal operations. The Stallion Journal study on “Data Governance in Lakehouse” shows why: organizations using metadata-driven governance, automation, and ML reported compliance rates rising to 92% for GDPR and HIPAA—use that as a north star benchmark, not a guarantee.
“Security is a process, not a product—and governance is how you keep that process honest.”
—Bruce Schneier
Map controls to regulations: your core compliance toolkit
You don’t “do GDPR” or “do HIPAA” by writing policies alone. You map requirements to repeatable controls inside the lakehouse:
- RBAC (role-based access control): limit who can see PHI/PII and who can export it.
- Audit trails lakehouse: prove who accessed what, when, from where, and what they did.
- Data lineage: show where sensitive fields came from, how they changed, and where they landed.
- Policy enforcement: apply masking, retention, and purpose limits consistently across tools.
- Metadata management + catalog: classify data, tag sensitivity, and drive automation.
| Regulation | What auditors look for | Lakehouse control |
|---|---|---|
| GDPR | Lawful access, minimization, retention | RBAC, masking, retention policies, lineage |
| HIPAA | Access logs, safeguards, least privilege | Audit trails, RBAC, encryption, monitoring |
| CCPA | Data inventory, access/deletion handling | Catalog + metadata, lineage, policy workflows |
The next wave: region-specific rules and legacy constraints
The paper flags future work you should plan for now: region-specific compliance and better adaptability for legacy or constrained environments. If you operate across states or countries, build policies that can vary by region (retention windows, consent rules, breach reporting). If you still run older systems, start with a smaller scope and integrate gradually—automation helps, but complexity is real.
“Audit day” walkthrough: what you’ll need to show
- Data inventory: where PII/PHI lives, owners, and purpose (
catalog + tags). - Access evidence: RBAC roles, approvals, and audit trails lakehouse exports.
- Lineage proof: source-to-report paths for key datasets and sensitive columns.
- Policy proof: masking, retention, deletion workflows, and enforcement logs.
- People in the room: data owner, security, platform admin, compliance/legal, and one analyst who uses the data.
Radar view: baseline vs governed lakehouse
Small, honest aside: if you’re a smaller org, start with a simple baseline—RBAC, logging, and a lightweight catalog—before you buy enterprise tooling. The study is clear that implementation complexity can be a real barrier, especially when resources are tight.
7) Vendor bias, politics, and the stuff governance decks skip
You can design a clean lakehouse governance model on paper, then watch it bend the moment data governance tooling enters the room. The uncomfortable reality is simple: tools and vendors shape what “best practice” looks like, because they shape what’s easy to demo, easy to buy, and easy to report.
The Stallion Journal lakehouse study calls this out directly in its conflict-of-interest section. It flags three bias sources you should assume are present in any governance program: vendor bias (favoring platforms like Collibra Talend governance stacks or other commercial suites), organizational reporting bias (only sharing “success” metrics), and financial/regulatory pressures (choosing what looks safest to auditors, not what fits your architecture). The research insight is clear: transparency and disclosure are necessary to preserve research integrity and keep your governance choices useful beyond vendor narratives.
Satya Nadella: “Trust is the ultimate currency—and in data, you earn it by being explicit about what you did and why.”
Bias risks you should name out loud
Your anti-bias checklist (practical, not political)
- Sampling: compare at least one commercial suite and one open option across AWS, Snowflake, Databricks, SAP, and Oracle Cloud Infrastructure ecosystems.
- Disclosure: document sponsors, tool selection reasons, and what you did not test.
- Evaluation criteria: lineage depth, RBAC/ABAC fit, audit trails, API access, export formats, and integration with your lakehouse tables.
- Proof-of-value: run a time-boxed pilot on one domain; measure policy enforcement time, error rate, and user friction.
- Vendor risk data platform check: ask how lock-in shows up in metadata, catalogs, and workflow rules.
Mini story: you mediate the real decision
Procurement pushes one vendor for “standardization.” Engineers want open source for control. Compliance wants “certified” features and clean audit evidence. Your job is to translate: you can meet compliance with strong controls and audit trails, meet engineers with APIs and portability, and meet procurement with clear ROI—without letting any one group define governance as “whatever the tool sells.”
What if your tool gets acquired and pricing triples?
Assume it can happen. Test portability now: can you export your business glossary, lineage, and policy rules in usable formats? If your metadata cannot move, your governance is not a program—it’s a subscription.
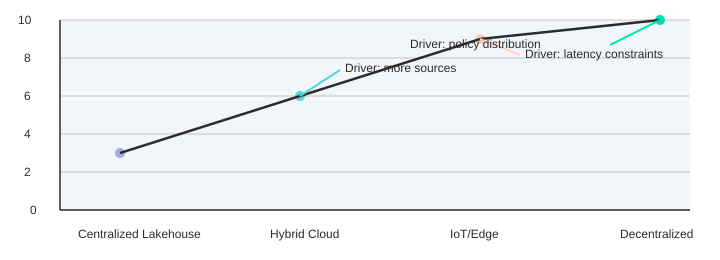
8) Future-proofing: IoT, edge, decentralized data, and the lakehouse you’ll inherit
Your lakehouse governance works best when data is mostly centralized, batch-friendly, and controlled by a few platforms. IoT and edge computing governance breaks those assumptions fast: you face more sources (devices, gateways, apps), less central control (teams deploy independently), and tighter latency limits (you cannot “wait for the nightly job” to decide access or quality). The Stallion Journal study flags this pressure directly and recommends governance extensions for three emerging domains: IoT data lakes, decentralized architectures, and edge computing.
Why IoT and edge stress your current model
With IoT streams, the same “customer” event can arrive from multiple sensors, in different formats, at different times. If your policies depend on a single central catalog update, you will either slow down operations or accept blind spots. Edge locations also create local copies of data for speed and resilience, which means your audit trails, lineage, and retention rules must travel with the data—not stay trapped in one warehouse-style control plane.
Decentralized data architecture needs portable governance
In a decentralized data architecture, domains publish data products and evolve schemas on their own schedules. That is healthy for delivery speed, but risky if your definitions of “PII,” “consent,” or “HIPAA scope” are not consistent. Future-proofing means you design governance as a shared service: extensible metadata, versioned policies, and identity controls that work across teams and regions, aligning with the paper’s call for region-specific compliance adaptability.
Build on cloud-native blocks you can inherit
The reference set around the study points you to practical building blocks: Docker for packaging policy services, Kubernetes for running them everywhere, Kafka for streaming enforcement hooks, Elasticsearch for fast discovery, and Postgres/PySpark for governed processing. You are not choosing tools for fashion—you are choosing what can run in the cloud, on-prem, and at the edge with the same controls.
“Everything fails, all the time—design governance like you expect change, not stability.” — Werner Vogels
A small-bet roadmap that keeps you moving
You do not need to solve edge governance fully today. You do need metadata and policy systems that can extend without rewrites. Start by piloting AI-driven anomaly detection on governance signals (schema drift, unusual access paths, out-of-pattern exports), then expand to automated policy checks at ingestion and at query time. As your footprint grows, add stronger identity management, consider blockchain-style tamper evidence for critical audit trails, and plan disaster recovery that matches your risk tier.
| Environment | Governance Complexity Index (illustrative) |
|---|---|
| Centralized Lakehouse | 3 |
| Hybrid Cloud | 6 |
| IoT/Edge | 9 |
| Decentralized | 10 |
Write your governance principles like you’ll be replaced: clear definitions, portable policies, and decision logs that survive reorganizations. The lakehouse you inherit later will be messier than today, and future-you will sleep better if you design for that now.
microsoft fabric lakehouse architecture: understand microsoft fabric for analytics and data engineering
What is Microsoft Fabric lakehouse architecture?
Microsoft Fabric lakehouse architecture is a unified data platform design that combines elements of data lakes and data warehouses to store raw data and structured, transformed datasets in a single location. It leverages Azure Data Lake Storage for data volumes, Fabric compute engines for processing, and medallion architecture patterns to manage raw, enriched, and curated layers so teams can analyze data, run data science workloads, and power reports in Power BI without duplicating data.
How does the medallion architecture work in a Fabric lakehouse?
The medallion architecture in Fabric organizes data into layers—typically bronze (raw data), silver (cleaned and enriched), and gold (curated analytics/BI-ready). Fabric integrates data ingestion and data transformation tools to move and transform data across layers, enabling data engineering and data preparation workflows that maintain a single copy of your data and reduce data duplication while supporting analytics and data science.
How do I implement a lakehouse in Microsoft Fabric and create a lakehouse?
To implement a lakehouse in Microsoft Fabric, start by connecting your data sources and ingest data into an Azure Data Lake using Fabric data ingestion capabilities. Use Fabric compute engines or dataflow transformations to apply medallion architecture processing, catalog datasets in OneLake, and secure access. Integrate Power BI and other analytics tools for reporting. The platform simplifies data management, supports data integration across existing data and big data, and lets you transform data without moving data unnecessarily.
What is the difference between a lakehouse and a traditional data warehouse in Microsoft Fabric?
A lakehouse combines the flexibility of data lakes for raw and semi-structured data with the performance and schema management of a data warehouse. In Microsoft Fabric, the lakehouse allows storing data in Azure Data Lake Storage while providing warehouse-like query performance via Fabric compute engines. This enables capabilities of a data warehouse—such as curated, structured data for analytics—while retaining the flexibility of a data lake for modern data and data engineering tasks.
How does Fabric handle data ingestion and avoid data duplication?
Fabric supports multiple data ingestion patterns—streaming, batch, and connectors to enterprise data sources—into a central lake (Azure Data Lake). Using medallion architecture and OneLake, Fabric promotes a single copy of your data and logical datasets rather than duplicating physical copies. Data integration and transformation tools let you ingest data, transform data in place, and provide consistent data access to analytics and data science workloads, minimizing duplicating data across systems.
Can I use existing data warehouses and Azure data alongside a Fabric lakehouse?
Yes. Fabric integrates with Microsoft and third-party systems, enabling you to federate queries to existing data warehouses, synapse, and Azure Data Lake Storage while consolidating data estate access. You can ingest or reference existing data, implement data mesh patterns, and choose whether to move data into the lakehouse or access it directly depending on governance, cost, and performance needs.
What are the common use cases for a Fabric lakehouse in analytics and data science?
Common use cases include unified data management for BI with Power BI, preparing large raw datasets for machine learning and data science, building ELT pipelines using medallion architecture, analyzing data across enterprise systems, and creating a single location for structured and unstructured data. Fabric simplifies data processing, enables scalable analyzing data and supports modern data architectures like data mesh and enterprise data catalogs.
How does security, governance, and data access work in a Fabric lakehouse?
Fabric provides role-based access control, data policies, and integration with Microsoft Purview and Azure Active Directory for governance and data lineage. OneLake and lakehouse constructs enable fine-grained permissions on data stored in Azure Data Lake Storage, ensuring secure data access, compliance, and controlled data preparation workflows while maintaining auditability across data ingestion and transformation steps.
Which Fabric compute engines should I use for different workloads in the lakehouse?
Fabric provides multiple compute engines optimized for specific workloads: interactive SQL queries for analytics and BI, Spark for big data processing and data engineering, and specialized engines for real-time ingestion. Choose Fabric compute engines based on workload characteristics—use Spark for large-scale transformations, warehouse SQL for BI queries, and streaming engines for continuous ingest to balance cost, performance, and data processing needs.
Where can I learn more and get started with Microsoft Fabric lakehouse architecture?
To get started, follow Microsoft Learn tutorials, review documentation on lakehouse architecture in Microsoft Fabric, and explore examples of medallion architecture in Fabric. Begin by connecting a data source, ingesting raw data into Azure Data Lake Storage, implementing a simple medallion pipeline, and visualizing results in Power BI to understand how Fabric simplifies creating a lakehouse and delivering analytics from a unified data estate.

Founder of M365 Show, M365con.net & m365.fm
Mirko Peters is a Microsoft 365 expert, content creator, and founder of m365.fm, a platform dedicated to sharing practical insights on modern workplace technologies. His work focuses on Microsoft 365 governance, security, collaboration, and real-world implementation strategies.
Through his podcast and written content, Mirko provides hands-on guidance for IT professionals, architects, and business leaders navigating the complexities of Microsoft 365. He is known for translating complex topics into clear, actionable advice, often highlighting common mistakes and overlooked risks in real-world environments.
With a strong emphasis on community contribution and knowledge sharing, Mirko is actively building a platform that connects experts, shares experiences, and helps organizations get the most out of their Microsoft 365 investments.
Microsoft Teams Phone Overview: Transforming Communication for Modern Businesses








