


This episode explains that cloud environments promise efficiency, elasticity, and control — but without governance engineered as architecture, they become financial drains and operational chaos. It recounts how idle resources, ungoverned permissions, and unmanaged sprawl can drive huge waste, and why governance first — not optimization after-the-fact — unlocks structural efficiency and sustained cost reduction. Listeners learn a practical 12-month cloud governance playbook that turns governance from reactive cost-cutting into proactive architectural discipline.






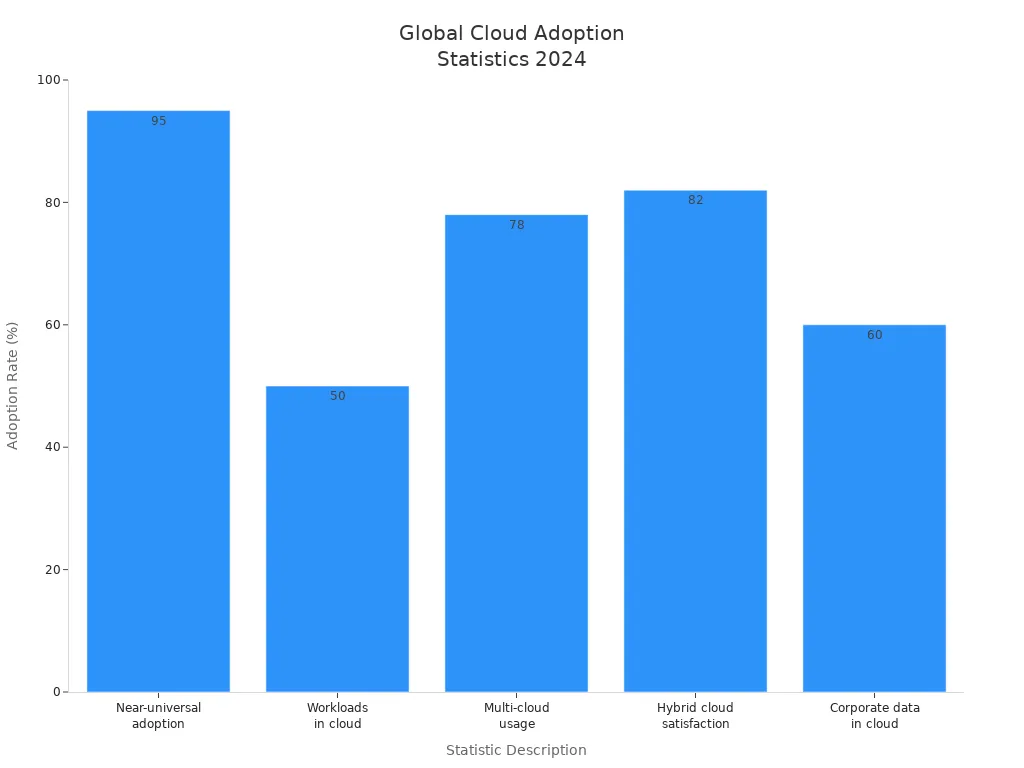
High-performance cloud computing plays a vital role in today's digital landscape. You can leverage its capabilities to manage large workloads and deliver reliable services. As organizations increasingly adopt cloud solutions, understanding how to design these systems becomes essential. Statistics show that over 94-96% of companies now use cloud services, with about 50% of their workloads running in public clouds. This shift highlights the necessity for effective engineering in cloud environments to maximize efficiency and reduce costs.
Key Takeaways
- Understand scalability to manage increased workloads effectively. Implement autoscaling to adjust resources based on demand.
- Prioritize reliability by establishing service-level agreements (SLAs) with cloud providers. This builds customer trust and prevents revenue losses.
- Maximize efficiency by adopting robust governance strategies. Monitor cloud spending to prevent waste and ensure financial efficiency.
- Leverage cloud architectures that support flexibility and resilience. This ensures your systems can adapt to changing business needs.
- Utilize virtualization to enhance resource allocation and simplify workload management. This leads to better performance in cloud environments.
- Adopt containerization for modular application deployment. This approach allows for quick scaling and improved performance.
- Implement continuous integration practices to automate software development. This leads to faster deployments and reduced risks.
- Use monitoring tools to track key performance indicators (KPIs). This helps maintain system health and optimize resource usage.
Principles of High-Performance Cloud
High-performance cloud systems rely on several core principles that ensure they meet the demands of modern businesses. Understanding these principles helps you design and manage cloud environments effectively.
Scalability
Scalability is the ability of a system to grow and manage increased loads by adding resources. This principle is crucial for maintaining performance during peak usage times. Here are some key points about scalability:
- Scalability allows applications to handle increased loads without performance degradation.
- It supports business continuity during rapid growth or peak periods.
- Effective scalability leads to improved user experiences and optimized costs.
To achieve scalability, consider implementing strategies such as autoscaling, which adjusts resources based on real-time demand. This approach can reduce costs significantly while ensuring that performance remains stable during high traffic periods. Additionally, using techniques like database sharding and elastic load balancers can enhance your system's ability to distribute workloads efficiently.
| Principle | Description |
|---|---|
| Scalability | The ability of a system to enhance its capacity as the load increases by adding more resources. |
| Reliability | Ensures the system delivers required functionality and continues to operate despite component failures. |
| Performance | Aims to minimize time taken and maximize data transfer quantities. |
| Security | Protects data and applications from unauthorized access and threats. |
| Cost Efficiency | Focuses on economical usage of cloud resources to achieve operational efficiency. |
Reliability
Reliability is another essential principle of high-performance cloud systems. It ensures that your cloud environment consistently delivers the required functionality. Here are some insights into reliability:
- Cloud providers establish service-level agreements (SLAs) that guarantee specific performance and uptime metrics.
- Reliability engineering is crucial for maintaining high availability and performance in cloud services.
- A focus on reliability builds customer trust and satisfaction while preventing revenue losses.
Recent industry reports show that leading cloud providers, such as Amazon Web Services and Microsoft Azure, maintain high reliability metrics. They achieve this through proactive measures and extensive performance data. For instance, CoreWeave achieved the ClusterMAX™ Platinum tier, indicating top-tier reliability and performance.
Efficiency
Efficiency in cloud computing is about maximizing resource usage while minimizing waste. Governance plays a vital role in achieving this efficiency. Here are some practices that enhance cloud efficiency:
- Implement robust Identity and Access Management (IAM) to control access to cloud resources.
- Prioritize security and compliance by adopting proactive measures such as encryption and regular assessments.
- Continuously monitor and optimize governance strategies to ensure they align with business needs.
Continuous governance ensures that cloud resources are utilized securely and cost-effectively. This structured approach allows you to adapt quickly to changing needs while maintaining security and compliance. Effective governance involves tracking cloud spending and setting budgets, which helps prevent waste and ensures financial efficiency.
By focusing on scalability, reliability, and efficiency, you can engineer high-performance cloud systems that meet the demands of your organization.
High-Performance Cloud Technologies
High-performance cloud technologies form the backbone of modern cloud computing. They enable organizations to optimize their operations and enhance performance. Understanding these technologies is essential for leveraging the full potential of cloud environments.
Cloud Architectures
Cloud architectures define how various components of cloud systems interact. A well-designed architecture supports high-performance workloads and ensures efficient resource utilization. For instance, in market risk analysis, orchestration software manages numerous compute nodes to run simulations. This setup allows for parallel processing, significantly enhancing computational efficiency.
Key elements of effective cloud architectures include:
- Scalability: The ability to grow resources as demand increases.
- Flexibility: Adapting to changing business needs without significant downtime.
- Resilience: Ensuring systems remain operational even during failures.
Virtualization
Virtualization plays a crucial role in enhancing performance in cloud systems. It enables multiple virtual instances to operate on a single physical server. This maximizes resource utilization and allows for efficient management of applications and workloads. By abstracting the physical infrastructure, virtualization facilitates scalable and flexible cloud environments.
Benefits of virtualization include:
- Improved resource allocation.
- Enhanced isolation of applications.
- Simplified management of workloads.
Containerization
Containerization has transformed how applications are deployed and managed in cloud environments. It allows you to package applications and their dependencies into containers. This modular approach simplifies scaling since services operate independently.
Here are some performance benefits of containerization:
| Performance Benefit | Description |
|---|---|
| Scalability | Containerization allows for quick scaling of resources to meet changing business demands. |
| Flexibility | It provides flexibility across cloud environments, enabling seamless application deployment. |
| Improved Performance | Continuous monitoring and predictive auto-scaling enhance performance and reliability. |
| Load Balancing | Distributes traffic to prevent bottlenecks, ensuring consistent application performance. |
| Fault Tolerance | Increases fault tolerance, reducing the impact of potential failures on user experience. |
High-performance computing (HPC) integrates seamlessly into cloud environments, enhancing computational power. HPC enables businesses to process large datasets and perform complex simulations. This capability leads to significant advancements in efficiency and productivity across various sectors, including finance, healthcare, and manufacturing.
By leveraging cloud-native microservices, you can further improve performance. Microservices architecture allows applications to be divided into smaller, independent services. This modular approach facilitates quicker development, testing, and deployment. As a result, you can adapt to new requirements or technologies more efficiently.
Performance Metrics for Cloud Systems
Measuring the performance of cloud systems is crucial for ensuring they meet your organization's needs. You can achieve this by focusing on key performance indicators (KPIs) and utilizing effective monitoring tools.
Key Performance Indicators
Key performance indicators help you assess the efficiency and effectiveness of your cloud systems. Here are some of the most commonly used KPIs:
- Response time: This metric measures the total time it takes for a system to respond to a user request. A lower response time indicates better performance.
- Throughput: This refers to the number of transactions or requests the system can handle in a given time period. Higher throughput means your system can manage more users simultaneously.
- Error rate: This percentage indicates how many requests result in errors. A lower error rate signifies greater system stability.
- Resource utilization: This includes metrics like CPU usage, memory consumption, disk I/O, and network bandwidth. Monitoring these helps you optimize resource allocation.
- Elasticity: This measures how well the system scales in response to changing loads. Effective elasticity ensures that your system can handle fluctuations in demand.
- User experience: Metrics such as page load times and user satisfaction scores provide insights into how users perceive your system's performance.
- Cost-related metrics: Understanding the cost per transaction or cost per user helps you manage expenses effectively.
By tracking these KPIs, you can gain valuable insights into your cloud system's performance and make informed decisions to enhance its efficiency.
Monitoring Tools
Monitoring tools play a vital role in maintaining high performance in cloud systems. They help you detect issues before they escalate, ensuring the reliability and availability of your services. Here are some key contributions of monitoring tools:
- They allow you to track KPIs that indicate system health and performance.
- Monitoring tools provide insights into performance indicators such as throughput, latency, memory usage, and response time.
- They enable proactive management by identifying patterns and anomalies in real-time data.
- Automated responses to events, like scaling resources during traffic spikes, enhance system performance.
Additionally, monitoring tools measure uptime and downtime, indicating service availability. They also assess response time, showing how quickly your system reacts to requests. Resource utilization metrics help you evaluate the efficiency of your resource usage.
By implementing a proactive performance engineering framework with effective monitoring tools, you can ensure that your high-performance systems operate smoothly and efficiently. This approach allows you to maintain optimal performance while minimizing costs and maximizing user satisfaction.
Best Practices for Cloud Optimization

Optimizing your cloud environment is essential for achieving high performance. Implementing best practices can significantly enhance your system's efficiency and reliability. Here are some strategies to consider:
Load Balancing
Load balancing is crucial for distributing workloads evenly across multiple instances. This practice prevents any single instance from becoming a bottleneck. Here are some effective load balancing strategies:
- Distribute workloads across multiple instances to optimize load average.
- Employ auto-scaling to adjust resources automatically based on demand.
- Optimize application code for better efficiency.
- Regularly monitor performance metrics to adjust resource allocation and maintain optimal load balancing.
By implementing these strategies, you can ensure that your cloud environment remains responsive and efficient, even during peak usage times.
Caching Strategies
Caching can significantly improve the performance of your cloud applications. By storing frequently accessed data in a cache, you reduce the time it takes to retrieve information. Here are some effective caching strategies:
- Use in-memory caching solutions like Redis or Memcached to speed up data retrieval.
- Implement content delivery networks (CDNs) to cache static assets closer to users, reducing latency.
- Regularly review and update your cache policies to ensure they align with current application needs.
These strategies help you minimize response times and enhance user experience, making your cloud applications more efficient.
Continuous Integration
Continuous integration (CI) enhances the performance and reliability of your cloud systems. It automates the software development process, allowing for faster and more reliable deployments. Here’s how CI can benefit your cloud environment:
| Key Aspect | Description |
|---|---|
| CI/CD Pipelines for Faster Deployments | Automates the build, test, and release process, leading to quicker software updates with reduced risk. Companies using CI/CD see a 70% reduction in deployment failures. |
| Automated Testing | Prevents regression issues, ensuring new updates do not disrupt existing functionality, especially in decentralized teams. |
| Regular Maintenance and Updates | Keeps systems secure and up to date with patches and vulnerability fixes, ensuring system trustworthiness. |
By adopting continuous integration practices, you can streamline your development process and maintain high performance in your cloud systems.
High-Performance Cloud Governance
High-performance cloud governance is essential for managing cloud environments effectively. A governance-first methodology aligns your cloud management practices with business outcomes. This approach reduces friction in processes and ensures that your cloud resources are utilized efficiently.
Governance Strategies
Implementing robust governance strategies is crucial for maintaining control over your cloud environment. Here are some core strategies to consider:
| Governance Strategy | Description |
|---|---|
| Cloud Governance Framework | Establishes policies and guidelines for controlled cloud service consumption aligned with business objectives. |
| Cloud Service Catalog | A list of approved services that standardizes consumption and mitigates risks. |
| Cloud Service Management | Manages the lifecycle of cloud services, defining roles and responsibilities. |
| Cloud Security | Implements security controls to ensure compliance and protect against vulnerabilities. |
| Cloud Cost Management | Monitors and optimizes spending to prevent unexpected costs. |
| Cloud Compliance | Ensures adherence to laws and industry standards through regular assessments. |
| Cloud Risk Management | Identifies risks and implements mitigation strategies aligned with business objectives. |
These strategies help you maintain a structured governance approach, which is vital for achieving high performance in cloud environments. Without effective structural governance, you risk uncontrolled resource sprawl and unexpectedly high cloud bills. This can degrade efficiency and lead to financial strain.
Financial Oversight
Financial oversight plays a significant role in the efficiency and sustainability of high-performance cloud systems. By establishing robust cost management controls, you ensure effective utilization of cloud resources. This reduces waste and helps you avoid unnecessary expenses. Here are some key practices to consider:
| Cost Management Practice | Impact on Efficiency and Sustainability |
|---|---|
| Establishing robust cost management controls | Ensures effective utilization of cloud resources, reducing waste and costs. |
| Monitoring continuous development environments | Prevents unnecessary expenses from unused testing infrastructure. |
| Managing backup and replication of data | Eliminates costs associated with retaining obsolete data. |
| Avoiding oversupplied resources | Reduces excess provisioning, leading to optimized resource use. |
| Controlling egress or bandwidth charges | Prevents unexpected high charges, maintaining budget efficiency. |
Additionally, traditional budgeting processes can lead to overprovisioning, negating cloud savings. Identifying and eliminating wasteful consumption is crucial for maximizing cloud benefits. Focusing on optimizing margins rather than merely reducing costs supports sustainable growth.
Policy Enforcement
Effective policy enforcement mechanisms are vital for maintaining governance in cloud computing. Here are some essential components to consider:
| Component | Description |
|---|---|
| Policies and Standards | Establishes rules for resource usage, access, and security measures, ensuring consistency and reducing risks. |
| Security and Risk Management | Implements access controls and regular audits to protect data and infrastructure, identifying threats and mitigation strategies. |
| Compliance and Regulatory Adherence | Aligns cloud usage with industry standards and legal requirements, using tools for monitoring compliance and addressing violations. |
| Cost Management and Optimization | Involves tracking spending and optimizing costs through budget settings and resource management rules to ensure financial efficiency. |
| Monitoring and Automation | Uses tools for continuous monitoring of resource usage and security events, automating policy enforcement to reduce manual oversight. |
| Roles and Responsibilities | Clearly defines accountability for managing resources and responding to incidents, ensuring governance is a shared effort across departments. |
By implementing these components, you create a framework that supports effective governance. This framework enables you to maintain control over your cloud resources while ensuring compliance and security.
Case Studies in High-Performance Cloud
Company A: Achieving Scalability
Company A faced challenges with fluctuating workloads. To overcome these issues, they focused on enhancing their cloud infrastructure's scalability. They implemented several key strategies that contributed to their success:
- Resource Management: Efficiently managing resources allowed Company A to adapt to varying demands. They monitored usage patterns and adjusted resources accordingly.
- Cost Optimization: Establishing a budget and cost goals helped minimize expenses while maximizing ROI. This approach ensured that they could scale without overspending.
- Cloud Services Utilization: Leveraging specific cloud services, such as auto-scaling and serverless computing, enhanced their ability to scale resources dynamically. This flexibility allowed them to respond quickly to changes in demand.
By adopting these strategies, Company A successfully scaled its operations. They improved performance during peak times and maintained a seamless user experience. This case illustrates how effective resource management and cloud services can drive scalability in high-performance cloud environments.
Company B: Enhancing Reliability
Company B prioritized reliability in their cloud systems to ensure consistent service delivery. They recognized that downtime could lead to significant revenue losses and customer dissatisfaction. To enhance reliability, they implemented several best practices:
- Redundancy: Company B established redundant systems to ensure that if one component failed, another could take over. This approach minimized downtime and maintained service availability.
- Regular Testing: They conducted regular testing of their systems to identify potential weaknesses. This proactive measure allowed them to address issues before they affected users.
- Monitoring Tools: Utilizing advanced monitoring tools enabled Company B to track performance metrics in real-time. They could quickly identify and resolve issues, ensuring high availability.
These practices helped Company B achieve impressive reliability metrics. Their commitment to maintaining operational performance built customer trust and satisfaction. This case highlights the importance of proactive measures in enhancing reliability within high-performance cloud systems.
In summary, you must prioritize engineering high-performance cloud systems to meet your organization's needs. Focus on scalability, reliability, and efficiency to enhance your cloud performance. Implementing strong governance practices will help you manage resources effectively and reduce costs. As you explore these principles, consider how they can transform your cloud environment into a powerful asset. Embrace these strategies to unlock the full potential of your cloud solutions.
FAQ
What is high-performance cloud computing?
High-performance cloud computing refers to cloud services designed to handle large workloads efficiently. It enables organizations to run complex applications and process vast amounts of data quickly.
How does high performance computing benefit businesses?
High performance computing allows businesses to analyze large datasets, run simulations, and improve decision-making. It enhances productivity and reduces time-to-market for new products.
What are the key components of high-performance cloud architecture?
Key components include scalability, reliability, and efficiency. These elements ensure that your cloud environment can handle varying workloads while maintaining performance and minimizing costs.
How can I optimize my cloud resources?
You can optimize resources by implementing load balancing, caching strategies, and continuous integration practices. These methods help you manage workloads effectively and reduce waste.
What role does governance play in cloud efficiency?
Governance ensures that your cloud resources are used effectively and securely. It helps prevent resource sprawl, reduces costs, and aligns cloud usage with business objectives.
How can I measure the performance of my cloud systems?
You can measure performance using key performance indicators (KPIs) such as response time, throughput, and error rate. Monitoring tools also provide insights into system health and resource utilization.
What are some common challenges in high-performance cloud environments?
Common challenges include managing costs, ensuring security, and maintaining compliance. Organizations must also address resource sprawl and optimize performance to achieve desired outcomes.
How can I ensure my cloud environment remains reliable?
To ensure reliability, implement redundancy, conduct regular testing, and utilize monitoring tools. These practices help you identify issues early and maintain high availability.
1
00:00:00,000 --> 00:00:05,040
A CFO sits at her desk on a Tuesday morning in March, staring at an Azure bill that just arrived.
2
00:00:05,040 --> 00:00:11,240
The total is $2.8 million higher than it was last quarter, and the most unsettling part is that nobody can explain why.
3
00:00:11,240 --> 00:00:19,560
She calls her "Cloud Architect" but he has no immediate answers, and her finance team is already digging through reports from six months ago to find the leak.
4
00:00:19,560 --> 00:00:27,760
This is the exact moment the internal narrative collapses. A high bill is a problem you can solve, but a bill that nobody can justify is a systemic failure.
5
00:00:27,760 --> 00:00:33,920
Organizations migrate to the cloud because they are promised elasticity, cost savings, and total control over their infrastructure.
6
00:00:33,920 --> 00:00:39,760
In reality, the environment often transforms into a financial black hole that consumes budget without producing equivalent value.
7
00:00:39,760 --> 00:00:42,040
This wasn't a random spike or a one-time mistake.
8
00:00:42,040 --> 00:00:46,200
When you look at the underlying architecture, this outcome was actually inevitable.
9
00:00:46,200 --> 00:00:47,720
The day finance noticed.
10
00:00:47,720 --> 00:00:52,120
Six months ago, this company believed their cloud adoption strategy was bulletproof.
11
00:00:52,120 --> 00:01:03,160
They had successfully moved workloads out of on-premises data centers, decommissioned their old physical servers, and celebrated their new cloud first mindset during company-wide meetings.
12
00:01:03,160 --> 00:01:10,600
The leadership team spoke about being modern, agile, and efficient, but that narrative was fundamentally detached from how the system was actually behaving.
13
00:01:10,600 --> 00:01:14,320
While the executive celebrated, the architecture was quietly eroding.
14
00:01:14,320 --> 00:01:20,240
Reserved instances set completely unused because no one had taken the time to classify which workloads were actually permanent.
15
00:01:20,240 --> 00:01:23,000
You cannot effectively commit to a three-year reservation.
16
00:01:23,000 --> 00:01:26,800
If you have no idea which services will remain stable over that period.
17
00:01:26,800 --> 00:01:31,560
To avoid being locked into the wrong contract, teams defaulted to pay as you go pricing.
18
00:01:31,560 --> 00:01:36,960
They thought they were being safe by staying flexible, but they were actually choosing the most expensive path possible.
19
00:01:36,960 --> 00:01:42,160
At the same time, zombie virtual machines from failed pilot programs continue to draw power and budget.
20
00:01:42,160 --> 00:01:48,480
A team might have spun up a proof of concept for a new application 18 months ago, and when the project failed, they simply walked away.
21
00:01:48,480 --> 00:01:53,440
Because those machines were never decommissioned, they stayed on the bill, silently charging the company month after month.
22
00:01:53,440 --> 00:02:02,080
When you multiply that single, forgotten experiment across a hundred different teams, you end up wasting hundreds of thousands of dollars on infrastructure that serves no purpose.
23
00:02:02,080 --> 00:02:07,200
The problem was made worse by dev and test environments that stayed active 24 hours a day.
24
00:02:07,200 --> 00:02:14,800
Provisioning in the cloud is frictionless, requiring only a few API calls to stand up an entire environment, but deprovisioning requires actual governance.
25
00:02:14,800 --> 00:02:22,000
Since nobody built a mechanism to enforce shutdowns, these environments ran through every weekend, every night, and every holiday.
26
00:02:22,000 --> 00:02:26,960
The very elasticity that was supposed to save the company money ended up making it easier to automate waste.
27
00:02:26,960 --> 00:02:31,760
Most leadership teams assume that cloud elasticity translates directly into automatic efficiency.
28
00:02:31,760 --> 00:02:32,600
It does not.
29
00:02:32,600 --> 00:02:38,880
Elasticity is simply a tool that allows you to scale up quickly, which is useful for performance, but dangerous for your budget.
30
00:02:38,880 --> 00:02:45,360
Without a deterministic policy to enforce cleanup, elasticity acts as a cost accelerant rather than a saving mechanism.
31
00:02:45,360 --> 00:02:51,040
Finance failed to notice the problem until month 13 because the total cloud spend was still lower than the old data center costs.
32
00:02:51,040 --> 00:02:57,680
They were comparing their current spending against a legacy past instead of comparing it against what a well-architected system should actually cost.
33
00:02:57,680 --> 00:03:03,920
The architecture was so inefficient that it was still cheaper than physical hardware, but it was underperforming by orders of magnitude.
34
00:03:03,920 --> 00:03:10,960
There is a massive gap between adopting Azure and actually understanding Azure cost architecture, and most enterprises are currently trapped in that space.
35
00:03:10,960 --> 00:03:16,480
They have moved the workloads and shutdown the buildings, but they haven't engineered the system for efficiency.
36
00:03:16,480 --> 00:03:21,600
They simply move their existing problems from a physical space into a virtual one and called it a success.
37
00:03:21,600 --> 00:03:24,640
This is the uncomfortable truth. The cloud does not make you efficient.
38
00:03:24,640 --> 00:03:28,800
It only gives you the capability to be efficient if you have the discipline to manage it.
39
00:03:28,800 --> 00:03:36,560
True efficiency requires an architect who is willing to say no to purposeless provisioning and enforce strict tagging and utilization standards.
40
00:03:36,560 --> 00:03:38,800
Most companies stop once they reach the cloud.
41
00:03:38,800 --> 00:03:45,280
They never move into the phase where they engineer the environment for deterministic costs, which is exactly where the millions of dollars are hidden.
42
00:03:45,280 --> 00:03:48,640
The CFO's 2.8 million dollar surprise wasn't an anomaly.
43
00:03:48,640 --> 00:03:57,760
It was the moment the gap between intent and configuration finally became too large to ignore the anatomy of waste, part one, idle infrastructure.
44
00:03:57,760 --> 00:04:00,800
Waste doesn't announce itself with a warning or a notification.
45
00:04:00,800 --> 00:04:05,680
Instead, it hides in the quiet gaps between what you intended to build and what you actually implemented.
46
00:04:05,680 --> 00:04:10,080
It lives within resources that were provisioned for a specific reason that no longer exists.
47
00:04:10,080 --> 00:04:12,480
Yet the system continues to treat them as active.
48
00:04:12,480 --> 00:04:19,520
This debt accumulates silently month after month until the bill arrives, and at that point nobody in the room can explain why the numbers are so high.
49
00:04:19,520 --> 00:04:22,080
Let's look at the actual mechanics of waste in Azure.
50
00:04:22,080 --> 00:04:28,080
The numbers are brutal but they are remarkably consistent across every enterprise that hasn't engineered for architectural determinism.
51
00:04:28,080 --> 00:04:32,800
Between 27 and 32% of clouds bend simply evaporates into orphaned resources.
52
00:04:32,800 --> 00:04:37,440
This includes unattached disks, snapshots from virtual machines that were deleted months ago,
53
00:04:37,440 --> 00:04:41,520
and abandoned storage accounts created for temporary projects that were never cleaned up.
54
00:04:41,520 --> 00:04:46,240
You also have managed disks sitting idle because the person who created them forgot they existed,
55
00:04:46,240 --> 00:04:49,760
along with IP addresses that are reserved but not currently in use.
56
00:04:49,760 --> 00:04:52,000
These are not edge cases or rare mistakes.
57
00:04:52,000 --> 00:04:57,840
They are the standard default outcome when provisioning is frictionless but deprovisioning requires someone to actually care.
58
00:04:57,840 --> 00:05:00,560
A single unattached disk in Azure costs money.
59
00:05:00,560 --> 00:05:07,040
While $5 a month per disk doesn't sound like much, the problem changes entirely when you scale that across a global enterprise.
60
00:05:07,040 --> 00:05:14,000
One company discovered 42 unattached disks they didn't know about, while another found 217 just sitting in their tenant.
61
00:05:14,000 --> 00:05:24,240
When you multiply those $5 by the number of disks and then by 12 months, the waste starts to compound invisibly because most enterprises never audit these resources until someone forces their hand.
62
00:05:24,240 --> 00:05:26,880
Then we have the persistent problem of dev and test environments.
63
00:05:26,880 --> 00:05:34,560
These workloads are supposed to run during business hours and shut down on nights or weekends yet they often run 24/7 because automation requires governance.
64
00:05:34,560 --> 00:05:42,240
Because governance requires someone to actually implement a policy, these servers stay active and continue to build the company for doing absolutely nothing.
65
00:05:42,240 --> 00:05:46,160
A single forgotten default virtual machine costs $730 every month.
66
00:05:46,160 --> 00:05:56,800
If you scale that across 200 forgotten instances, you are looking at $146,000 a month which adds up to $1.7 million a year for idle compute.
67
00:05:56,800 --> 00:06:00,400
This pattern repeats across every enterprise with mechanical consistency.
68
00:06:00,400 --> 00:06:05,120
You provision a resource, you forget it exists, the bill arrives and then the leadership team panics.
69
00:06:05,120 --> 00:06:09,360
This isn't a matter of individual incompetence, it is a failure of architecture.
70
00:06:09,360 --> 00:06:15,280
The system is designed to make provisioning easy and deprovisioning difficult so waste naturally becomes the path of least resistance.
71
00:06:15,280 --> 00:06:21,200
A global manufacturing firm discovered this reality the hard way when they realized 42% of their compute was sitting idle.
72
00:06:21,200 --> 00:06:28,560
They had no visibility into what was actually being used versus what was just consuming resources so they didn't catch the trend until month 13.
73
00:06:28,560 --> 00:06:32,080
Once they finally started measuring the environment, the picture became clear.
74
00:06:32,080 --> 00:06:37,760
They had thousands of VMs, storage accounts and disks that were running at less than 5% utilization.
75
00:06:37,760 --> 00:06:40,400
The intervention for this type of entropy is straightforward.
76
00:06:40,400 --> 00:06:46,960
You must measure utilization for 30 to 90 days and then classify every workload by its specific usage pattern.
77
00:06:46,960 --> 00:06:53,520
Once you have that data you can write size based on actual consumption and implement scheduled shutdowns for every non-production environment.
78
00:06:53,520 --> 00:06:58,720
Enforcing a strict tagging policy ensures you actually know what you own, allowing you to delete what has been orphaned.
79
00:06:58,720 --> 00:07:00,800
The outcome of these steps is predictable.
80
00:07:00,800 --> 00:07:08,400
Organizations typically see a 22 to 35% reduction in compute costs and a 10% drop across their entire Azure estate.
81
00:07:08,400 --> 00:07:16,400
Payback usually happens within 120 days and after that the changes result in pure savings month after month but here's the uncomfortable architectural truth.
82
00:07:16,400 --> 00:07:18,240
The waste was never the cloud's fault.
83
00:07:18,240 --> 00:07:21,280
It was the result of a total absence of workload architecture.
84
00:07:21,280 --> 00:07:28,160
The company had migrated their infrastructure without understanding what they were moving treating every VM like a steady state production asset.
85
00:07:28,160 --> 00:07:34,560
Because they didn't classify things as experimental or temporary everything defaulted to pay as you go and everything stayed running forever.
86
00:07:34,560 --> 00:07:36,560
This is the first anatomy of waste.
87
00:07:36,560 --> 00:07:40,400
It isn't hidden in complex pricing models or exotic configurations.
88
00:07:40,400 --> 00:07:44,960
It is sitting right in front of you in the form of idle resources and forgotten assets.
89
00:07:44,960 --> 00:07:49,600
It represents nearly a third of your bill and it is just waiting for someone to measure it and turn it off.
90
00:07:49,600 --> 00:07:51,600
The cynical architects observation is simple.
91
00:07:51,600 --> 00:07:52,880
You don't have a cost problem.
92
00:07:52,880 --> 00:07:56,160
You have a visibility problem and you cannot fix what you refuse to see.
93
00:07:56,880 --> 00:08:00,080
The anatomy of waste, part two, the SaaS sprawl trap.
94
00:08:00,080 --> 00:08:05,280
Idl infrastructure is only half the story and the other half lives within the chaos of licensing.
95
00:08:05,280 --> 00:08:09,440
This waste is often worse because it is invisible in a way that virtual machines are not.
96
00:08:09,440 --> 00:08:16,640
You can see a server sitting in a subscription but you cannot see a power app that was built once used for a month and then abandoned by its creator.
97
00:08:16,640 --> 00:08:22,080
You cannot see the duplicate automation that three different teams built because they had no idea what their colleagues were doing.
98
00:08:22,080 --> 00:08:24,720
The pattern is easy to spot once you know where to look.
99
00:08:24,720 --> 00:08:32,960
An enterprise might have nearly five thousand power apps spread across their tenant but telemetry usually shows that 62% of them were never opened after the first 90 days.
100
00:08:32,960 --> 00:08:38,160
Nobody is maintaining these apps and nobody is paying attention to them yet they continue to consume licenses and storage.
101
00:08:38,160 --> 00:08:43,520
They sit there rotting in the environment like digital zombies because there is no life cycle management to clean them up.
102
00:08:43,520 --> 00:08:49,360
When there is no connector governance or data loss prevention policy every new business need results in a new silo.
103
00:08:49,360 --> 00:09:00,240
Instead of checking for existing tools someone spins up a new power app with its own environment and its own data connectors because there is no central visibility the organization ends up building the same business logic six different times.
104
00:09:00,240 --> 00:09:05,120
This proliferation creates massive redundancy and that redundancy is where the real waste lives.
105
00:09:05,120 --> 00:09:10,400
The cost isn't found in the platform itself it is found in the unmanaged growth of the ecosystem.
106
00:09:10,400 --> 00:09:18,640
One enterprise was paying for 12,000 e5 licenses even though their own usage data showed that only 28% of users needed those security features.
107
00:09:18,640 --> 00:09:26,160
The rest of the staff only required basic email and collaboration tools meaning the company was over-licensed by orders of magnitude.
108
00:09:26,160 --> 00:09:36,320
This licensing debt compounded because nobody was asking whether people actually needed the maximum capability they were assigned fixing this requires discipline across three specific dimensions.
109
00:09:36,320 --> 00:09:42,560
First you must implement environment stratification to create strict boundaries between production sandbox and personal areas.
110
00:09:42,560 --> 00:09:53,600
You cannot allow people to build in production and then wonder why your governance model is breaking. Second you need an inactive app lifecycle policy that automatically archives or deletes tools that haven't been touched in six months.
111
00:09:53,600 --> 00:09:56,880
This isn't an act of cruelty it is basic digital hygiene.
112
00:09:56,880 --> 00:10:02,320
Third you must enforce connector governance by requiring architectural reviews for custom integrations.
113
00:10:02,320 --> 00:10:08,240
You cannot have every user building their own connections because that removes all visibility into your data flows.
114
00:10:08,240 --> 00:10:15,680
Organizations that implement these controls consistently see a 30 to 50% reduction in licenses and a significant drop in support tickets.
115
00:10:15,680 --> 00:10:21,760
When you force consolidation you force visibility and that allows you to actually architect your system instead of just accumulating debt.
116
00:10:21,760 --> 00:10:25,680
The cynical architects inside here is different from the idle infrastructure problem.
117
00:10:25,680 --> 00:10:32,400
With infrastructure the issue is that nobody turn things off but with SAS sprawl the issue is that nobody said no to turning things on.
118
00:10:32,400 --> 00:10:40,160
Permission without policy always scales to chaos if you give people the ability to create environments and provision licenses without boundaries they will do exactly that.
119
00:10:40,160 --> 00:10:46,000
This is the second anatomy of waste. It isn't about idle compute it is about the cost of permission without policy.
120
00:10:46,000 --> 00:10:52,480
It is the price you pay for licenses that nobody uses and duplicate automation that exists because of a lack of central governance.
121
00:10:52,480 --> 00:11:01,120
For most enterprises this sprawl represents nearly half of their Microsoft 365 spend and it will continue to grow until someone enforces a design.
122
00:11:01,120 --> 00:11:09,600
The anatomy of waste, part three shadow AI and ungovernance experimentation then copilot arrived and suddenly waste took on an entirely new shape.
123
00:11:09,600 --> 00:11:16,800
For years enterprises managed cloud spending through a predictable lens where virtual machines storage and licenses cost a known amount of money.
124
00:11:16,800 --> 00:11:22,240
This waste was visible and measurable and once you actually paid attention it was relatively easy to control.
125
00:11:22,240 --> 00:11:26,000
AI workloads changed that by introducing a new dimension of risk.
126
00:11:26,000 --> 00:11:34,480
These systems are orders of magnitude more expensive to waste than traditional infrastructure and because they scale faster they are much harder to track in real time.
127
00:11:34,480 --> 00:11:37,760
Consider what happened at one specific FinTech organization.
128
00:11:37,760 --> 00:11:47,200
Leadership decided copilot was strategic and transformative so they licensed 12,000 seats without any formal governance or data readiness assessments.
129
00:11:47,200 --> 00:11:52,480
Everyone received access immediately but no one set up quota controls or usage guardrails.
130
00:11:52,480 --> 00:11:57,280
Developers began provisioning Azure OpenAI endpoints simply because they had the permission to do so
131
00:11:57,280 --> 00:12:01,200
and token usage exploded across the environment without any central visibility.
132
00:12:01,200 --> 00:12:12,240
The infrastructure tax hit them hard. Gateway costs always on compute and safety filtering are built separately from token pricing, creating a massive overhead that exists solely to support these AI workloads.
133
00:12:12,240 --> 00:12:18,880
By the time the architectural bill arrived the organization was paying $340,000 a month for Azure OpenAI alone.
134
00:12:18,880 --> 00:12:24,880
That figure didn't even include the copilot licensing, the storage for embeddings or the compute required for fine tuning.
135
00:12:24,880 --> 00:12:30,800
They were spending millions a year on a capability that hadn't produced a single measurable business outcome.
136
00:12:30,800 --> 00:12:32,320
The intervention had to be surgical.
137
00:12:32,320 --> 00:12:37,680
They started by enforcing sensitivity labeling and cleaning up SharePoint to remove orphaned sites and duplicate files.
138
00:12:37,680 --> 00:12:44,000
Once the data was handled they replaced the 12,000 seat free for all with a pilot cohort of 400 power users.
139
00:12:44,000 --> 00:12:51,840
This allowed them to measure adoption and ROI before expanding while simultaneously implementing hard limits on tokens per user and per application.
140
00:12:51,840 --> 00:12:57,760
If a user hit their limit the system stopped, there were no exceptions and no automatic overages. The outcome was dramatic.
141
00:12:57,760 --> 00:13:03,600
By moving from a probabilistic model of hope for the best to a deterministic model of enforced the limit,
142
00:13:03,600 --> 00:13:09,120
the organization reduced its monthly spend from $340,000 to $68,000.
143
00:13:09,120 --> 00:13:13,840
That represents an 80% cost reduction while actually maintaining productivity gains.
144
00:13:13,840 --> 00:13:19,120
They enabled real innovation by stopping the undisciplined burning of capital on experiments that had no guardrails.
145
00:13:19,120 --> 00:13:24,080
This pattern is consistent across every organization that fails to govern AI before it scales.
146
00:13:24,080 --> 00:13:27,440
Permission without policy is a recipe for architectural erosion.
147
00:13:27,440 --> 00:13:34,240
While copilot is powerful and Azure OpenAI is capable, capability without governance is just an expensive way to fail.
148
00:13:34,240 --> 00:13:40,000
When you are dealing with token-based pricing at scale, expensive experimentation can quickly lead to financial ruin.
149
00:13:40,000 --> 00:13:42,400
This is the cynical architects inside.
150
00:13:42,400 --> 00:13:46,240
You don't actually have a copilot adoption problem. You have a data governance problem.
151
00:13:46,240 --> 00:13:51,760
Copilot is a distributed decision engine that amplifies access to whatever data exists in your environment.
152
00:13:51,760 --> 00:13:56,000
If your share point is a mess, copilot makes that mess accessible to everyone at scale.
153
00:13:56,000 --> 00:14:03,040
If your sensitivity labels are inconsistent, the AI will bypass that inconsistency and expose sensitive data anyway.
154
00:14:03,040 --> 00:14:09,840
The risk isn't the tool itself, but the act of deploying it into an ungoverned environment and being shocked when it does exactly what you told it to do.
155
00:14:09,840 --> 00:14:14,240
The lesson is brutal. Shadow AI is not a user problem. It is an architecture problem.
156
00:14:14,240 --> 00:14:20,080
It emerges because you gave people permission to experiment without building the governance infrastructure to control those experiments.
157
00:14:20,080 --> 00:14:25,440
Because AI workloads scale so much faster than traditional infrastructure, the consequences are amplified.
158
00:14:25,440 --> 00:14:33,200
A forgotten virtual machine might cost you $700 a month, but an ungoverned, open AI endpoint can easily cost $700,000.
159
00:14:33,200 --> 00:14:39,760
Most organizations don't see the shadow AI problem until the bill arrives and by then the tokens are consumed and the data is already exposed.
160
00:14:39,760 --> 00:14:44,000
At that point, your only option is remediation, which is always more expensive than design.
161
00:14:44,000 --> 00:14:47,680
You are forced into governance after the fact instead of governance by design.
162
00:14:47,680 --> 00:14:52,800
The cynical architects' final observation is simple. You cannot optimize what you do not govern.
163
00:14:52,800 --> 00:14:57,280
With AI, the measurement and the guardrails must exist before you scale not after.
164
00:14:57,280 --> 00:15:04,000
The cost of waiting is no longer a rounding error. It is measured in hundreds of thousands of dollars every single month.
165
00:15:04,000 --> 00:15:06,400
The governance reckoning, what actually changed.
166
00:15:06,400 --> 00:15:08,160
This is where the story shifts.
167
00:15:08,160 --> 00:15:13,200
Every enterprise that successfully reclaimed millions of dollars in lost spend followed the same path.
168
00:15:13,200 --> 00:15:19,360
They stopped provisioning resources without permission and stopped treating the cloud like an infinite pool of resources.
169
00:15:19,360 --> 00:15:24,560
They moved away from the assumption that elasticity automatically equals efficiency and started focusing on engineering.
170
00:15:24,560 --> 00:15:29,280
The CFO's voice usually leads this shift. Finance needs to know who is spending money and why,
171
00:15:29,280 --> 00:15:32,480
which is a fundamental business requirement rather than a technical request.
172
00:15:32,480 --> 00:15:38,320
If an architect cannot explain which team is consuming which resources, the budget becomes impossible to forecast.
173
00:15:38,320 --> 00:15:43,600
Without that clarity, leadership is just watching a number grow on a bill and hoping it eventually stops.
174
00:15:43,600 --> 00:15:49,600
The enterprise architect usually responds by pointing out that visibility without policy is just a way to report on failure.
175
00:15:49,600 --> 00:15:53,520
You can see the waste but without guardrails you lack the mechanism to stop it.
176
00:15:53,520 --> 00:15:56,960
Visibility is a necessary first step but it is never sufficient on its own.
177
00:15:56,960 --> 00:15:59,280
You need a system that is capable of saying no.
178
00:15:59,280 --> 00:16:01,920
The cynical cloud architect adds the final truth.
179
00:16:01,920 --> 00:16:06,000
You cannot govern what you do not measure but you also cannot scale governance reactively.
180
00:16:06,000 --> 00:16:12,320
You have to build control into the system itself as a foundation rather than a compliance layer bolted on as an afterthought.
181
00:16:12,320 --> 00:16:16,640
This is where the transition from best practice to enforced architecture happens.
182
00:16:16,640 --> 00:16:20,080
Azure Policy became the mandatory control plane for these organizations.
183
00:16:20,080 --> 00:16:27,920
Every subscription inherited a baseline set of rules that enforced tagging and prevented certain resource types from being created without prior approval.
184
00:16:27,920 --> 00:16:33,040
These policies also enforced encryption and blocked public access to storage accounts by default.
185
00:16:33,040 --> 00:16:37,520
These weren't suggestions or guidelines. They were hard coded rules that were non-negotiable.
186
00:16:37,520 --> 00:16:39,760
Tagging enforcement was the next logical step.
187
00:16:39,760 --> 00:16:44,880
Every resource had to be labeled with a cost center, an environment, an owner and an application name.
188
00:16:44,880 --> 00:16:50,560
If a developer tried to create a resource without those specific tags, the system rejected the request immediately.
189
00:16:50,560 --> 00:16:57,760
This force discipline at the moment of creation which is far more effective than trying to retrofit metadata on to thousands of orphaned resources months later.
190
00:16:57,760 --> 00:17:03,120
Environmenteering followed creating strict boundaries between production, sandbox and personal environments.
191
00:17:03,120 --> 00:17:07,200
You cannot test in production and you cannot run permanent workloads in a sandbox.
192
00:17:07,200 --> 00:17:13,040
These boundaries were enforced at the policy layer so that if a user tried to violate them, the system simply stopped the action.
193
00:17:13,040 --> 00:17:16,000
The first 90 days of this transition are always chaotic.
194
00:17:16,000 --> 00:17:20,400
Teams push back because they hate the friction and operations groups complain about the new overhead.
195
00:17:20,400 --> 00:17:25,840
The common argument is that the cloud was supposed to be fast, but now it feels slow because it requires planning and governance.
196
00:17:25,840 --> 00:17:30,480
However, a shift occurs around the three-month mark as the chaos settles into a predictable rhythm.
197
00:17:30,480 --> 00:17:33,440
Teams begin to realize that the friction isn't arbitrary.
198
00:17:33,440 --> 00:17:37,280
It is forcing them to think about what they are building before they provision it.
199
00:17:37,280 --> 00:17:44,240
It forces them to classify their workloads and understand the difference between an experimental project and a permanent production service.
200
00:17:44,240 --> 00:17:46,160
The following 90 days look very different.
201
00:17:46,160 --> 00:17:51,280
Waste becomes visible not as an abstract number, but as a concrete pattern of behavior.
202
00:17:51,280 --> 00:17:58,800
If a team provisions 100 virtual machines and 90 of them sit idle, that failure is now undeniable and attributed to a specific owner.
203
00:17:58,800 --> 00:18:04,160
Accountability changes how people behave. When teams know their waste is being measured and attributed to their budget,
204
00:18:04,160 --> 00:18:05,760
they start to care about right sizing.
205
00:18:05,760 --> 00:18:10,560
They begin to shut down what isn't being used, not because they are being forced to buy a central authority,
206
00:18:10,560 --> 00:18:13,440
but because they can finally see the impact of their own decisions.
207
00:18:13,440 --> 00:18:18,320
The CFO eventually notes that the organization stopped guessing and started measuring.
208
00:18:18,320 --> 00:18:21,840
The Enterprise Architect adds that they stopped reacting and started designing.
209
00:18:21,840 --> 00:18:26,000
Finally, the cynical cloud architect concludes that they stopped assuming the cloud was cheaper
210
00:18:26,000 --> 00:18:27,760
and started engineering it to be.
211
00:18:27,760 --> 00:18:31,840
The results for organizations that implement this model are remarkably consistent.
212
00:18:31,840 --> 00:18:36,240
They see sustained cost reductions of 25 to 35 percent that last for years.
213
00:18:36,240 --> 00:18:37,520
These aren't one-time wins.
214
00:18:37,520 --> 00:18:40,800
They are the result of governance becoming a discipline rather than a project.
215
00:18:40,800 --> 00:18:42,800
It becomes baked into the operating model.
216
00:18:42,800 --> 00:18:44,560
The lesson is purely architectural.
217
00:18:44,560 --> 00:18:48,560
Cost optimization is not a financial problem to be solved by accountants.
218
00:18:48,560 --> 00:18:51,120
It is a governance problem to be solved by architects.
219
00:18:51,120 --> 00:18:53,200
Governance is the foundation of the system.
220
00:18:53,200 --> 00:18:58,080
And everything else, efficiency, security, and scale follows from that initial design.
221
00:18:58,080 --> 00:19:03,200
Case Study 1, the manufacturing firm, reserved instances and workload classification.
222
00:19:03,200 --> 00:19:06,720
Let's look at a pattern that has repeated across dozens of enterprises,
223
00:19:06,720 --> 00:19:10,480
specifically a global manufacturing company with 6000 employees,
224
00:19:10,480 --> 00:19:12,560
spread across multiple continents.
225
00:19:12,560 --> 00:19:16,320
They had migrated their entire infrastructure to Azure 18 months prior
226
00:19:16,320 --> 00:19:18,640
and on the surface the migration was a success.
227
00:19:18,640 --> 00:19:23,680
Servers were decommissioned, data centers were closed, and the company proudly claimed a cloud-first posture,
228
00:19:23,680 --> 00:19:27,840
but the underlying architecture was broken in ways that nobody had bothered to measure.
229
00:19:27,840 --> 00:19:32,080
When the governance reckoning finally started, the raw numbers revealed the depth of the problem.
230
00:19:32,080 --> 00:19:35,200
42 percent of their compute was running on pay as you go pricing,
231
00:19:35,200 --> 00:19:38,080
not because the workloads were variable or required flexibility,
232
00:19:38,080 --> 00:19:40,080
but because nobody had bothered to classify them.
233
00:19:40,080 --> 00:19:43,840
They didn't know which systems were steady state and which were experimental,
234
00:19:43,840 --> 00:19:47,200
so everything defaulted to the most expensive option available.
235
00:19:47,200 --> 00:19:49,760
This meant they were consuming resources at full price,
236
00:19:49,760 --> 00:19:52,800
with no commitment and absolutely no discount.
237
00:19:52,800 --> 00:19:55,760
18 percent of that compute set idle or underutilized,
238
00:19:55,760 --> 00:19:58,320
running at less than 5 percent CPU utilization,
239
00:19:58,320 --> 00:20:01,360
while still generating heat and billing the company for the privilege.
240
00:20:01,360 --> 00:20:03,920
These weren't orphaned resources in the traditional sense,
241
00:20:03,920 --> 00:20:08,720
but rather workloads that someone had provisioned for a specific reason that had since changed.
242
00:20:08,720 --> 00:20:11,200
As the projects evolved and demand shifted,
243
00:20:11,200 --> 00:20:13,760
the infrastructure stayed exactly where it was,
244
00:20:13,760 --> 00:20:15,200
still running and still billing.
245
00:20:15,200 --> 00:20:19,840
0 percent of their estate was covered by savings plans because they had no commitment strategy,
246
00:20:19,840 --> 00:20:22,720
which is the inevitable result of having no workload classification.
247
00:20:22,720 --> 00:20:27,360
You cannot commit to three-year reserved instances if you don't know which workloads will stay stable,
248
00:20:27,360 --> 00:20:30,640
and you can't use one-year plans without understanding the difference between
249
00:20:30,640 --> 00:20:33,280
permanent infrastructure and temporary experiments.
250
00:20:33,280 --> 00:20:34,800
Because they chose to commit to nothing,
251
00:20:34,800 --> 00:20:39,360
they paid full price for everything and the monthly bill reflected that lack of intent.
252
00:20:39,360 --> 00:20:42,960
The intervention began with a forensic inventory of every virtual machine,
253
00:20:42,960 --> 00:20:46,320
database, storage account, and managed disk in the environment.
254
00:20:46,320 --> 00:20:49,680
This wasn't a theoretical exercise, it was a deep dive into what existed,
255
00:20:49,680 --> 00:20:53,520
who owned it, and what its actual utilization patterns looked like over time.
256
00:20:53,520 --> 00:20:56,240
We needed to move past what people thought the patterns were,
257
00:20:56,240 --> 00:21:01,360
and look at 30 to 90 days of hard data covering CPU, memory, and network traffic.
258
00:21:01,360 --> 00:21:02,560
The data was brutal,
259
00:21:02,560 --> 00:21:06,960
showing that most workloads were running at a tiny fraction of their provisioned capacity.
260
00:21:06,960 --> 00:21:10,320
A VM-sized for a peak load that never happened was wasting money every hour,
261
00:21:10,320 --> 00:21:14,560
and databases provisioned for thousands of concurrent connections were handling only a handful.
262
00:21:14,560 --> 00:21:18,720
The entire infrastructure had been built for worst-case scenarios that rarely materialized,
263
00:21:18,720 --> 00:21:22,160
creating a massive gap between provisioned costs and actual value.
264
00:21:22,160 --> 00:21:26,960
Classification finally allowed us to align the infrastructure with the right pricing models.
265
00:21:26,960 --> 00:21:30,640
Steady state production systems became candidates for reserved instances,
266
00:21:30,640 --> 00:21:34,800
which offered a 72% discount in exchange for a three-year commitment.
267
00:21:34,800 --> 00:21:39,360
Variable workloads like development environments were moved to spot VMs for a 90% discount,
268
00:21:39,360 --> 00:21:44,160
while experimental proof of concepts stayed on pay as you go with a strict deletion timer.
269
00:21:44,160 --> 00:21:47,360
Devin test environments were placed on an automated shutdown schedule
270
00:21:47,360 --> 00:21:50,720
that killed power at 6pm on weekdays and kept them off all weekend.
271
00:21:50,720 --> 00:21:54,640
This non-negotiable policy alone reclaimed nearly 40% of non-production spend
272
00:21:54,640 --> 00:21:58,800
because development infrastructure simply does not need to run when nobody is working.
273
00:21:58,800 --> 00:22:03,600
It had been running 24/7 only because nobody had built the automation to turn it off.
274
00:22:03,600 --> 00:22:06,880
Tag enforcement shifted the financial burden from a central IT budget
275
00:22:06,880 --> 00:22:11,280
to the specific business units consuming the resources, this created immediate accountability
276
00:22:11,280 --> 00:22:14,640
and when teams finally saw their own costs and understood what they were spending
277
00:22:14,640 --> 00:22:16,480
their behavior changed overnight.
278
00:22:16,480 --> 00:22:21,440
The result was a 35% reduction in compute costs and a full payback on the optimization project
279
00:22:21,440 --> 00:22:23,280
within 120 days.
280
00:22:23,280 --> 00:22:27,520
The architectural insight here is that the waste wasn't the fault of the cloud provider.
281
00:22:27,520 --> 00:22:30,880
The waste was caused by the total absence of workload architecture
282
00:22:30,880 --> 00:22:36,160
as the company had moved VMs from on-premises to the cloud without ever classifying them.
283
00:22:36,160 --> 00:22:41,040
Everything defaulted to expensive, everything stayed running and eventually everything was forgotten.
284
00:22:41,040 --> 00:22:42,560
The lesson is simple.
285
00:22:42,560 --> 00:22:45,200
Cost optimization isn't about hunting for discounts
286
00:22:45,200 --> 00:22:49,280
but about understanding your workloads well enough to match them to the right model.
287
00:22:49,280 --> 00:22:53,280
Reserved instances handle the steady state, spot VMs handle the variable
288
00:22:53,280 --> 00:22:54,960
and pay as you go is for experiments.
289
00:22:54,960 --> 00:22:58,000
If you get the classification right, the savings follow but if you get it wrong
290
00:22:58,000 --> 00:23:01,280
you're just paying full price for a mess and calling it cloud adoption.
291
00:23:01,280 --> 00:23:03,200
Case study 2
292
00:23:03,200 --> 00:23:06,560
The power platform tenant sprawl, environment governance.
293
00:23:06,560 --> 00:23:09,840
Reserved instances only fix the infrastructure side of the house
294
00:23:09,840 --> 00:23:13,920
but the other half of the problem lives in the Microsoft 365 ecosystem.
295
00:23:13,920 --> 00:23:18,400
This waste is more insidious because it is harder to see and even harder to quantify
296
00:23:18,400 --> 00:23:19,680
than a standard VM bill.
297
00:23:19,680 --> 00:23:24,720
One enterprise discovered they had 4,800 power apps spread across 47 different environments
298
00:23:24,720 --> 00:23:27,680
with no central governance or lifecycle management.
299
00:23:27,680 --> 00:23:31,040
62% of those apps were never opened after their initial deployment
300
00:23:31,040 --> 00:23:34,960
meaning they were just sitting there rotting while consuming licenses and storage.
301
00:23:34,960 --> 00:23:37,920
Nobody was maintaining them and nobody even knew they existed
302
00:23:37,920 --> 00:23:41,200
yet they added to the total governance overhead of the tenant.
303
00:23:41,200 --> 00:23:43,840
This happened because the organization lacked central visibility
304
00:23:43,840 --> 00:23:47,120
so whenever a business need emerged someone just spun up a new power app
305
00:23:47,120 --> 00:23:48,160
and a new environment.
306
00:23:48,160 --> 00:23:51,120
Instead of consolidating or checking for existing solutions
307
00:23:51,120 --> 00:23:54,320
teams built the same business logic six different times using their own
308
00:23:54,320 --> 00:23:56,320
custom connectors and data sets.
309
00:23:56,320 --> 00:24:00,640
When you multiply that behavior across a global organization
310
00:24:00,640 --> 00:24:05,040
you end up with massive redundancy and a platform that feels like a digital junkyard.
311
00:24:05,040 --> 00:24:09,120
Fixing this required discipline across several architectural dimensions
312
00:24:09,120 --> 00:24:13,280
starting with strict environment stratification between production, sandbox,
313
00:24:13,280 --> 00:24:14,480
and personal areas.
314
00:24:14,480 --> 00:24:16,880
You cannot have users building in production environments
315
00:24:16,880 --> 00:24:19,440
and then wonder why your governance model is breaking down.
316
00:24:19,440 --> 00:24:23,200
These boundaries must be enforced at the platform layer as hard rules
317
00:24:23,200 --> 00:24:27,120
rather than being suggested as optional guidelines for the staff to follow.
318
00:24:27,120 --> 00:24:32,720
Next we implemented an inactive app life cycle policy that marked any app not opened in 90 days for review.
319
00:24:32,720 --> 00:24:37,360
If an app reached 180 days of inactivity it was archived and at the one-year mark
320
00:24:37,360 --> 00:24:38,560
it was permanently deleted.
321
00:24:38,560 --> 00:24:42,960
This wasn't an act of cruelty but a necessary form of hygiene to remove the digital waste
322
00:24:42,960 --> 00:24:45,120
that was consuming storage and mental overhead.
323
00:24:45,120 --> 00:24:48,800
Connector governance was the third pillar requiring architecture reviews for
324
00:24:48,800 --> 00:24:51,840
custom integrations and formula approval for premium connectors.
325
00:24:51,840 --> 00:24:54,800
You cannot allow every user to build their own integrations
326
00:24:54,800 --> 00:24:59,200
because you lose all visibility into where your data is going and how it is being used.
327
00:24:59,200 --> 00:25:01,920
By forcing teams to use standard integrations
328
00:25:01,920 --> 00:25:06,560
we forced consolidation and finally gained a clear picture of the organization's data flows.
329
00:25:06,560 --> 00:25:10,000
Managed environment controls like conditional access and data loss prevention
330
00:25:10,000 --> 00:25:13,680
became the mandatory baseline for every production environment in the tenant.
331
00:25:13,680 --> 00:25:16,000
If a team wanted to use premium features
332
00:25:16,000 --> 00:25:19,680
they had to accept the governance that came with them as a non-negotiable tradeoff.
333
00:25:19,680 --> 00:25:23,440
This ensured that every high-value app was wrapped in the same security
334
00:25:23,440 --> 00:25:25,120
and ordered logging standards.
335
00:25:25,120 --> 00:25:30,320
The outcome mirrored the manufacturing case resulting in a 50% reduction in licenses
336
00:25:30,320 --> 00:25:32,880
and a 40% drop in support tickets.
337
00:25:32,880 --> 00:25:37,200
Teams finally discovered what they actually needed versus what they had built during a period
338
00:25:37,200 --> 00:25:39,120
of unmonitored experimentation.
339
00:25:39,120 --> 00:25:43,440
The real benefit was clarity because when you force consolidation you force visibility
340
00:25:43,440 --> 00:25:46,880
which allows you to actually architect a system instead of just accumulating dead.
341
00:25:46,880 --> 00:25:50,640
The architectural inside here is different from the compute case
342
00:25:50,640 --> 00:25:52,960
where the issue was failing to turn things off.
343
00:25:52,960 --> 00:25:57,280
With Power Platform sprawl the problem is that nobody ever said no to turning things on
344
00:25:57,280 --> 00:26:00,400
and permission without policy always scales toward chaos.
345
00:26:00,400 --> 00:26:04,880
If you give people the ability to create environments and provision connectors without boundaries
346
00:26:04,880 --> 00:26:07,920
you will end up with sprawl that compounds every single month.
347
00:26:07,920 --> 00:26:11,440
This is the second anatomy of waste and it isn't about idle servers
348
00:26:11,440 --> 00:26:15,440
but about the proliferation of unused licenses and duplicate automations.
349
00:26:15,440 --> 00:26:19,440
It is the literal cost of granting permission without enforcing a policy
350
00:26:19,440 --> 00:26:23,920
and for most enterprises this represents nearly half of their total Power Platform spend.
351
00:26:23,920 --> 00:26:28,000
This sprawl became the default because the organization never measured what was being used
352
00:26:28,000 --> 00:26:31,120
and they never enforced the boundaries required to keep the system clean.
353
00:26:31,120 --> 00:26:33,120
Case study 3
354
00:26:33,120 --> 00:26:36,720
The M365 license right sizing, utilization audit.
355
00:26:36,720 --> 00:26:40,640
The same pattern of architectural erosion appears in almost every enterprise
356
00:26:40,640 --> 00:26:43,200
Microsoft 365 deployment I review.
357
00:26:43,200 --> 00:26:48,160
Organizations over license their users because they fail to measure actual system interaction.
358
00:26:48,160 --> 00:26:52,320
In one specific case an enterprise deployed 12,000 e5 licenses
359
00:26:52,320 --> 00:26:55,760
across their entire global workforce based on a remarkably lazy assumption.
360
00:26:55,760 --> 00:27:00,160
They viewed e5 as the premium tier that simply includes everything from security features
361
00:27:00,160 --> 00:27:02,560
and advanced compliance to co-pilot capabilities.
362
00:27:02,560 --> 00:27:06,720
Management decided it was safer to over license than to risk under provisioning.
363
00:27:06,720 --> 00:27:10,240
They wanted to give every employee the premium experience
364
00:27:10,240 --> 00:27:13,680
believing the worst case scenario was merely a few unused features.
365
00:27:13,680 --> 00:27:17,200
In their minds the best case scenario was providing universal access
366
00:27:17,200 --> 00:27:19,680
to every tool a worker might eventually need.
367
00:27:19,680 --> 00:27:21,760
That assumption was architecturally flawed.
368
00:27:21,760 --> 00:27:25,360
When we looked at the actual usage telemetry the data told a much more clinical story.
369
00:27:25,360 --> 00:27:30,960
Only 28% of the user base actually touched the advanced security features that justify an e5 price tag.
370
00:27:30,960 --> 00:27:34,480
The remaining thousands of users were frontline workers and support staff
371
00:27:34,480 --> 00:27:38,800
who only required basic email calendar and standard collaboration tools.
372
00:27:38,800 --> 00:27:41,920
The organization had over license by orders of magnitude
373
00:27:41,920 --> 00:27:45,200
creating a massive pile of licensing debt that compounded every month
374
00:27:45,200 --> 00:27:47,440
because nobody was auditing utilization.
375
00:27:47,440 --> 00:27:51,760
No one bothered to ask if a user's role actually required the features they were assigned.
376
00:27:51,760 --> 00:27:56,640
They chose e5 for universal coverage but in reality they were just funding maximum waste.
377
00:27:56,640 --> 00:28:01,120
Fixing this required a level of discipline that most organizations find uncomfortable.
378
00:28:01,120 --> 00:28:04,880
You have to audit actual feature usage rather than just counting heads.
379
00:28:04,880 --> 00:28:08,240
Instead of asking how many people have an e5 you must ask
380
00:28:08,240 --> 00:28:11,520
how many are triggering the advanced compliance or e-discovery engines.
381
00:28:11,520 --> 00:28:16,000
You have to look at who is actually using information barriers or customer key encryption.
382
00:28:16,000 --> 00:28:19,040
When you look at the raw telemetry the answer is always the same.
383
00:28:19,040 --> 00:28:23,280
Only a tiny fraction of your users actually need those premium capabilities.
384
00:28:23,280 --> 00:28:25,040
The resulting rebalancing was surgical.
385
00:28:25,040 --> 00:28:29,280
We moved the core knowledge workers who actually utilized advanced security into e5.
386
00:28:29,280 --> 00:28:33,360
While frontline workers who only needed basic communication were shifted to f3.
387
00:28:33,360 --> 00:28:38,240
Support staff who required teams and sharepoint but didn't need a full mailbox were moved to e3.
388
00:28:38,240 --> 00:28:43,760
We also stripped away redundant add-ons that had been purchased just in case but sat dormant for years.
389
00:28:43,760 --> 00:28:45,040
This wasn't about being cheap.
390
00:28:45,040 --> 00:28:48,960
It was about matching the license to the actual technical requirement of the role.
391
00:28:48,960 --> 00:28:52,240
We ignored the theoretical maximums and the safe assumptions,
392
00:28:52,240 --> 00:28:55,520
focusing entirely on what the users were actually doing within the tenant.
393
00:28:55,520 --> 00:28:58,480
The financial outcome was immediate and undeniable.
394
00:28:58,480 --> 00:29:03,440
The organization saw a cost reduction of nearly 28% on their M365 spend
395
00:29:03,440 --> 00:29:05,440
without compromising their security posture.
396
00:29:05,440 --> 00:29:09,200
In fact the security posture improved because the organization finally understood
397
00:29:09,200 --> 00:29:12,640
which users needed specific controls and could enforce them more effectively.
398
00:29:12,640 --> 00:29:17,760
For a 12,000 ct state this resulted in 1.2 million dollars in annual savings.
399
00:29:17,760 --> 00:29:19,760
This wasn't a one-time negotiation win.
400
00:29:19,760 --> 00:29:22,640
It was a permanent reduction in the cost of doing business.
401
00:29:22,640 --> 00:29:25,440
There was a significant operational shift as well.
402
00:29:25,440 --> 00:29:28,240
Roles became more clearly defined through the lens of the license.
403
00:29:28,240 --> 00:29:33,840
Support staff understood their F3 assignment was a reflection of their specific need for teams and sharepoint.
404
00:29:33,840 --> 00:29:39,600
Knowledge workers understood their E5 status was tied to specific security and compliance responsibilities.
405
00:29:39,600 --> 00:29:43,920
The license stopped being a random seat assignment and became a statement of a person's role
406
00:29:43,920 --> 00:29:45,600
within the digital architecture.
407
00:29:45,600 --> 00:29:50,080
The cynical architects inside here is that licensing efficiency is a discipline,
408
00:29:50,080 --> 00:29:51,040
not a discount.
409
00:29:51,040 --> 00:29:54,240
You don't save money by begging for better rates during a renewal.
410
00:29:54,240 --> 00:29:59,200
You save money by understanding the specific needs of your environment and paying for exactly that.
411
00:29:59,200 --> 00:30:02,880
Most organizations fail here because they lack the stomach for ongoing measurement.
412
00:30:02,880 --> 00:30:08,160
They don't want to have the difficult conversation with a manager about why their team doesn't need premium licenses.
413
00:30:08,160 --> 00:30:12,720
This case study proves that waste isn't always about often VMs or idle storage.
414
00:30:12,720 --> 00:30:16,160
Sometimes waste is simply paying for a capability that no one is using.
415
00:30:16,160 --> 00:30:19,200
It is the gap between what you license and what you actually consume.
416
00:30:19,200 --> 00:30:26,080
When that gap is multiplied across 12,000 cts, it becomes a million dollar leak that continues until someone finally looks at the data and makes it stop.
417
00:30:26,080 --> 00:30:27,760
Case study 4.
418
00:30:27,760 --> 00:30:29,680
Copilot governance before scale.
419
00:30:29,680 --> 00:30:31,840
Data readiness and pilot control.
420
00:30:31,840 --> 00:30:37,520
One enterprise I worked with wanted to deploy Copilot across their entire organization as quickly as possible.
421
00:30:37,520 --> 00:30:42,800
Leadership was enamored with the promised productivity gains and the potential for a massive competitive advantage.
422
00:30:42,800 --> 00:30:45,440
Finance had already cleared the budget for a full rollout,
423
00:30:45,440 --> 00:30:48,000
but the security team stepped in and demanded a pause.
424
00:30:48,000 --> 00:30:51,280
That single decision saved the company from an architectural catastrophe.
425
00:30:51,280 --> 00:30:52,880
The underlying problem was structural.
426
00:30:52,880 --> 00:30:57,440
Their sharepoint environment was a disaster, sensitivity labels were applied inconsistently,
427
00:30:57,440 --> 00:31:01,440
and data governance existed only as a series of ignored PDF policies.
428
00:31:01,440 --> 00:31:04,480
Files were scattered across thousands of sites with no classification,
429
00:31:04,480 --> 00:31:07,200
meaning some confidential documents were labeled correctly,
430
00:31:07,200 --> 00:31:09,040
while others were completely exposed.
431
00:31:09,040 --> 00:31:14,160
It was a chaotic environment, and Copilot was about to amplify that chaos at an enterprise scale.
432
00:31:14,160 --> 00:31:19,360
If they had proceeded with the broad rollout, 12,000 users would have gained the ability to query the entire mess.
433
00:31:19,360 --> 00:31:23,280
Copilot would have synthesized answers from documents that should have been deleted years ago
434
00:31:23,280 --> 00:31:26,640
and surfaced sensitive information to people who had no business seeing it.
435
00:31:26,640 --> 00:31:29,920
Copilot doesn't fix a messy data architecture, it exposes it.
436
00:31:29,920 --> 00:31:34,800
It turns a quiet compliance risk into an active liability by making every forgotten file
437
00:31:34,800 --> 00:31:36,000
searchable and summarized.
438
00:31:36,000 --> 00:31:40,320
The intervention was disciplined and focused on a data hygiene first approach.
439
00:31:40,320 --> 00:31:43,520
They spent months doing the unglomerious work of cleaning up sharepoint
440
00:31:43,520 --> 00:31:46,320
by removing orphaned sites and consolidating duplicates.
441
00:31:46,320 --> 00:31:49,920
They made sensitivity labeling mandatory, rather than optional,
442
00:31:49,920 --> 00:31:52,080
ensuring every document had a classification,
443
00:31:52,080 --> 00:31:54,000
and every site had a retention policy.
444
00:31:54,000 --> 00:31:55,840
This wasn't innovation in the flashy sense,
445
00:31:55,840 --> 00:31:59,360
but it was the necessary foundation for any AI implementation.
446
00:31:59,360 --> 00:32:03,680
Once the data was under control, they launched a pilot for 400 power users
447
00:32:03,680 --> 00:32:05,440
instead of the full 12,000.
448
00:32:05,440 --> 00:32:09,520
This was a strategic move to measure adoption and ROI in a controlled environment.
449
00:32:09,520 --> 00:32:11,520
You don't just hope a tool like Copilot works,
450
00:32:11,520 --> 00:32:14,160
you measure the specific changes in how people work.
451
00:32:14,160 --> 00:32:17,760
By limiting the scope, they could monitor data exposure in real time
452
00:32:17,760 --> 00:32:21,440
and see exactly how the AI interacted with their newly cleaned environment,
453
00:32:21,440 --> 00:32:24,240
we used license gating to enforce this discipline.
454
00:32:24,240 --> 00:32:26,400
Licenses weren't handed out like candy.
455
00:32:26,400 --> 00:32:28,400
They were allocated strictly by roll.
456
00:32:28,400 --> 00:32:30,960
Engineering, product and sales teams were given access
457
00:32:30,960 --> 00:32:33,920
because their workflows were expected to show the highest impact.
458
00:32:33,920 --> 00:32:35,760
Support teams were excluded initially,
459
00:32:35,760 --> 00:32:37,120
not because their work wasn't important,
460
00:32:37,120 --> 00:32:39,840
but because the pilot needed to be a clean experiment.
461
00:32:39,840 --> 00:32:42,480
We also implemented strict conditional access controls
462
00:32:42,480 --> 00:32:46,160
to ensure Copilot was only reachable from managed encrypted devices.
463
00:32:46,160 --> 00:32:47,840
This wasn't an act of paranoia,
464
00:32:47,840 --> 00:32:50,880
but a necessary step when giving users an AI interface
465
00:32:50,880 --> 00:32:52,800
that can touch sensitive company data.
466
00:32:52,800 --> 00:32:56,640
If you are going to provide a tool that can summarize your entire intellectual property,
467
00:32:56,640 --> 00:32:59,200
you must control the endpoint where that data is displayed,
468
00:32:59,200 --> 00:33:00,800
the pilot ran for 90 days,
469
00:33:00,800 --> 00:33:03,120
and we measured everything with forensic detail.
470
00:33:03,120 --> 00:33:05,280
We tracked how often people used the tool,
471
00:33:05,280 --> 00:33:06,640
what tasks they performed,
472
00:33:06,640 --> 00:33:09,600
and whether any documents were accessed inappropriately.
473
00:33:09,600 --> 00:33:13,360
We wanted to know if the productivity gains were real or just marketing hype.
474
00:33:13,360 --> 00:33:14,560
The results were revealing,
475
00:33:14,560 --> 00:33:17,680
adoption was actually lower than the leadership had anticipated,
476
00:33:17,680 --> 00:33:20,240
while some teams found the tool indispensable,
477
00:33:20,240 --> 00:33:23,520
others found it largely irrelevant to their daily work.
478
00:33:23,520 --> 00:33:25,280
The data exposure was zero,
479
00:33:25,280 --> 00:33:27,440
and the compliance violations were nonexistent,
480
00:33:27,440 --> 00:33:30,400
but the ROI was merely positive rather than transformative.
481
00:33:30,400 --> 00:33:31,440
It was worth expanding,
482
00:33:31,440 --> 00:33:34,400
but it certainly wasn't the revolution the brochures promised,
483
00:33:34,400 --> 00:33:35,280
because we had the data,
484
00:33:35,280 --> 00:33:39,760
the organization decided to expand to 2000 seats rather than 12,000.
485
00:33:39,760 --> 00:33:42,320
The cynical architects' observation is that most companies
486
00:33:42,320 --> 00:33:44,400
don't actually have a copilot adoption problem.
487
00:33:44,400 --> 00:33:45,920
They have a data governance problem.
488
00:33:45,920 --> 00:33:49,360
This enterprise succeeded because they chose to govern before they scaled.
489
00:33:49,360 --> 00:33:53,280
They measured the impact before they committed millions of dollars to a full rollout.
490
00:33:53,280 --> 00:33:55,360
They understood the risk of their own data mess,
491
00:33:55,360 --> 00:33:58,640
and refused to expose it to an AI engine until it was cleaned.
492
00:33:58,640 --> 00:34:00,400
The lesson here is purely architectural.
493
00:34:00,400 --> 00:34:02,960
Scaling a system without governance isn't growth.
494
00:34:02,960 --> 00:34:05,600
It is just the accumulation of high-interest technical debt,
495
00:34:05,600 --> 00:34:09,680
with AI that debt compounds much faster than it does with traditional infrastructure.
496
00:34:09,680 --> 00:34:14,240
A single mistake in copilot governance can expose millions of documents to the wrong people.
497
00:34:14,240 --> 00:34:16,480
The only real defense is to enforce your assumptions
498
00:34:16,480 --> 00:34:19,040
through governance before you hit the scale button.
499
00:34:19,040 --> 00:34:20,400
Case Study 5
500
00:34:20,400 --> 00:34:22,800
Multi-region architecture consolidation
501
00:34:22,800 --> 00:34:25,040
Habspoke and landing zones.
502
00:34:25,040 --> 00:34:30,720
Infrastructure waste is rarely just a collection of often discs or oversized virtual machines.
503
00:34:30,720 --> 00:34:35,680
Because more often than not, it is a symptom of architectural redundancy.
504
00:34:35,680 --> 00:34:38,400
I recently looked at an enterprise that had managed to duplicate
505
00:34:38,400 --> 00:34:41,520
its entire environment across five different global regions.
506
00:34:41,520 --> 00:34:44,080
They were running redundant virtual networks and bleeding money
507
00:34:44,080 --> 00:34:48,080
through excess egress charges all because they lacked any form of landing zone enforcement.
508
00:34:48,080 --> 00:34:51,280
Each region was a unique snowflake with its own siloed policies
509
00:34:51,280 --> 00:34:53,280
and its own fragmented governance model.
510
00:34:53,280 --> 00:34:57,120
Provisioning was entirely ad hoc, so if a team needed infrastructure in Frankfurt,
511
00:34:57,120 --> 00:35:00,640
they simply built it from scratch and when another team needed a footprint in Singapore,
512
00:35:00,640 --> 00:35:02,000
they built it differently.
513
00:35:02,000 --> 00:35:04,800
There was no consistency, no standardization,
514
00:35:04,800 --> 00:35:07,280
and absolutely no architectural leverage.
515
00:35:07,280 --> 00:35:11,360
The financial fallout of this build-as-you-go approach was entirely predictable.
516
00:35:11,360 --> 00:35:13,920
Because redundant v-nets were scattered across the globe,
517
00:35:13,920 --> 00:35:17,760
data was forced to flow between regions in the most inefficient ways possible,
518
00:35:17,760 --> 00:35:20,800
causing egress charges to accumulate silently in the background.
519
00:35:21,440 --> 00:35:26,480
A single gigabyte of data moving from Azure Europe to Azure Asia Pacific cost money,
520
00:35:26,480 --> 00:35:29,680
and when you multiply that movement thousands of times a day,
521
00:35:29,680 --> 00:35:33,840
the build becomes a significant line item that nobody was actually measuring.
522
00:35:33,840 --> 00:35:37,120
No one was optimizing the pay thing because the architecture just happened by accident,
523
00:35:37,120 --> 00:35:39,840
and the monthly invoice simply reflected every inefficient
524
00:35:39,840 --> 00:35:42,480
rooting decision made by disconnected teams.
525
00:35:42,480 --> 00:35:44,400
The fix for this wasn't a cost-cutting exercise,
526
00:35:44,400 --> 00:35:46,240
but rather an architectural intervention,
527
00:35:46,240 --> 00:35:48,240
centered on a mandatory hub-spoke model.
528
00:35:48,240 --> 00:35:53,360
We moved away from the chaos by ensuring every region received a central hub virtual network
529
00:35:53,360 --> 00:35:55,600
with spoke networks attached directly to it.
530
00:35:55,600 --> 00:36:00,880
This created a centralized and standardized environment where data flows became intentional,
531
00:36:00,880 --> 00:36:02,000
rather than accidental.
532
00:36:02,000 --> 00:36:05,040
If data needed to move between regions, it traveled through the hub,
533
00:36:05,040 --> 00:36:07,920
but if it stayed within a region, it remained within the spoke.
534
00:36:07,920 --> 00:36:10,480
This shift wasn't just about changing the network topology,
535
00:36:10,480 --> 00:36:13,200
it was about forcing the system to behave predictably.
536
00:36:13,200 --> 00:36:16,800
Landing zone enforcement was the next logical step in regaining control.
537
00:36:16,800 --> 00:36:20,960
We reached a point where every new subscription inherited a baseline architecture
538
00:36:20,960 --> 00:36:22,960
that was mandatory rather than advisory.
539
00:36:22,960 --> 00:36:25,760
This meant the same network topology, the same policy framework,
540
00:36:25,760 --> 00:36:29,360
and the same tagging strategy were applied across the board without exception.
541
00:36:29,360 --> 00:36:32,640
Now, when a developer provisions a new subscription in Azure Europe,
542
00:36:32,640 --> 00:36:36,080
it arrives pre-configured with the hub-spoke model already in place.
543
00:36:36,080 --> 00:36:39,280
You don't have to design the security or implement the connectivity
544
00:36:39,280 --> 00:36:41,200
because the platform provides it by default,
545
00:36:41,200 --> 00:36:45,360
which effectively forced consistency across the entire global organization.
546
00:36:45,360 --> 00:36:49,920
Policy-driven provisioning ensured that no one could deviate from this established baseline.
547
00:36:49,920 --> 00:36:53,760
You simply could not create a virtual network that wasn't attached to the hub,
548
00:36:53,760 --> 00:36:57,360
nor could you spin up a subnet without the required metadata tags.
549
00:36:57,360 --> 00:37:00,080
If a user tried to create a storage account without encryption,
550
00:37:00,080 --> 00:37:02,240
the system rejected the request immediately.
551
00:37:02,240 --> 00:37:06,400
These weren't just helpful guidelines, they were hard rules enforced by the platform itself.
552
00:37:06,400 --> 00:37:08,640
By using the policy engine to guard the architecture,
553
00:37:08,640 --> 00:37:13,120
we successfully prevented the configuration drift that had plagued the organization for years.
554
00:37:13,120 --> 00:37:15,680
The outcome of these changes was measurable and immediate,
555
00:37:15,680 --> 00:37:19,680
resulting in a 12-20% reduction in total infrastructure costs.
556
00:37:19,680 --> 00:37:22,880
These savings didn't come from negotiating better discounts with Microsoft,
557
00:37:22,880 --> 00:37:27,680
but from pure architectural efficiency and the elimination of redundant networks.
558
00:37:27,680 --> 00:37:31,120
By optimizing data flows and cutting off the silent egress charges,
559
00:37:31,120 --> 00:37:34,720
the organization finally achieved a state of latency-aware cost balancing.
560
00:37:34,720 --> 00:37:38,720
They understood exactly where their data lived and where it needed to go,
561
00:37:38,720 --> 00:37:41,600
ensuring that workloads serving European customers stayed in Europe
562
00:37:41,600 --> 00:37:43,760
while Asian workloads stayed in Asia.
563
00:37:43,760 --> 00:37:47,120
Data stopped wandering across the globe and started flowing with purpose.
564
00:37:47,120 --> 00:37:49,360
Provisioning time also saw a massive improvement,
565
00:37:49,360 --> 00:37:51,920
dropping from three weeks down to just three days.
566
00:37:51,920 --> 00:37:55,040
This didn't happen because the people got faster at their jobs,
567
00:37:55,040 --> 00:37:59,680
but because the entire process was finally automated through the landing zone baseline.
568
00:37:59,680 --> 00:38:02,480
When the organization moved to a single reference implementation
569
00:38:02,480 --> 00:38:04,240
that everyone was forced to use,
570
00:38:04,240 --> 00:38:08,560
provisioning shifted from a creative exercise into a simple matter of configuration.
571
00:38:08,560 --> 00:38:12,480
You were no longer building a foundation from scratch every time a project started.
572
00:38:12,480 --> 00:38:15,680
You were merely toggling settings on a pre-built, optimized platform.
573
00:38:15,680 --> 00:38:18,320
The financial impact of this transition was substantial,
574
00:38:18,320 --> 00:38:22,160
totaling $340,000 in annual infrastructure savings.
575
00:38:22,160 --> 00:38:24,560
This wasn't a one-time cleanup or a lucky break,
576
00:38:24,560 --> 00:38:29,520
but rather a sustained reduction in spend because the architecture itself now enforced efficiency.
577
00:38:29,520 --> 00:38:34,000
Every new resource provisioned by the company inherited a cost-optimized baseline
578
00:38:34,000 --> 00:38:37,040
and every data flow followed the most efficient path possible.
579
00:38:37,040 --> 00:38:40,320
The entire global footprint finally operated under a single,
580
00:38:40,320 --> 00:38:43,840
unified governance framework that made waste difficult to achieve.
581
00:38:43,840 --> 00:38:47,120
The architectural insight here is subtle, but it is also profound.
582
00:38:47,120 --> 00:38:50,000
Architecture is the true control plane of your cloud environment
583
00:38:50,000 --> 00:38:52,080
and everything else you do is just execution.
584
00:38:52,080 --> 00:38:55,600
You can buy the most expensive cost-optimization tools on the market,
585
00:38:55,600 --> 00:38:58,480
but if your underlying architecture encourages waste,
586
00:38:58,480 --> 00:39:00,400
those tools will never be able to save you.
587
00:39:00,400 --> 00:39:03,600
You can write perfect governance policies in a PDF,
588
00:39:03,600 --> 00:39:06,960
but if your architecture makes it easy for people to violate them,
589
00:39:06,960 --> 00:39:08,560
they will find a way to do it.
590
00:39:08,560 --> 00:39:11,840
Even comprehensive monitoring is useless if the architecture is so complex
591
00:39:11,840 --> 00:39:14,000
that you can't interpret the data it produces.
592
00:39:14,000 --> 00:39:16,480
The organizations that successfully reclaimed millions of dollars
593
00:39:16,480 --> 00:39:19,200
didn't do it through better reporting or clever negotiation.
594
00:39:19,200 --> 00:39:21,360
They did it by making their architecture
595
00:39:21,360 --> 00:39:23,840
enforce the specific behaviors they wanted to see.
596
00:39:23,840 --> 00:39:26,320
They turned efficiency into the path of least resistance
597
00:39:26,320 --> 00:39:28,880
and made it harder to waste money than it was to optimize it.
598
00:39:28,880 --> 00:39:31,920
By making the default configuration, the right configuration,
599
00:39:31,920 --> 00:39:34,160
they removed the human element from the equation.
600
00:39:34,160 --> 00:39:36,720
This is the final lesson from these case studies.
601
00:39:36,720 --> 00:39:39,840
Cost-optimization is an architectural challenge, not a financial one.
602
00:39:39,840 --> 00:39:41,440
If you get the architecture right,
603
00:39:41,440 --> 00:39:44,000
the costs will naturally follow your design intent.
604
00:39:44,000 --> 00:39:45,680
If you get the architecture wrong,
605
00:39:45,680 --> 00:39:48,880
no amount of clever pricing models or reserved instances
606
00:39:48,880 --> 00:39:52,560
will be enough to save your budget from the inevitable entropy of the cloud.
607
00:39:52,560 --> 00:39:55,280
Designing determinism, the operating model.
608
00:39:55,280 --> 00:39:57,920
This is the point where theory finally meets practice.
609
00:39:57,920 --> 00:40:01,520
Every enterprise that has successfully reclaimed millions of dollars
610
00:40:01,520 --> 00:40:03,760
followed the same initial path.
611
00:40:03,760 --> 00:40:06,800
They stopped treating cost optimization as a temporary project.
612
00:40:06,800 --> 00:40:09,440
Instead, they baked efficiency into the structural DNA
613
00:40:09,440 --> 00:40:11,280
of how the organization functions.
614
00:40:11,280 --> 00:40:13,840
They built an operating model where saving money wasn't an optional
615
00:40:13,840 --> 00:40:16,880
nice to have feature, but a fundamental requirement of the system.
616
00:40:16,880 --> 00:40:19,760
The monthly FinOps board meeting became a mandatory ritual
617
00:40:19,760 --> 00:40:21,920
where engineering, finance and operations
618
00:40:21,920 --> 00:40:24,560
all sat in the same room to have the same difficult conversation.
619
00:40:24,560 --> 00:40:27,600
They looked at exactly what was spent, why the numbers moved
620
00:40:27,600 --> 00:40:29,920
and what the forecast looked like for the coming month.
621
00:40:29,920 --> 00:40:31,760
This wasn't a boring compliance meeting
622
00:40:31,760 --> 00:40:34,880
where reports were filed away and forgotten by the end of the day.
623
00:40:34,880 --> 00:40:38,160
It was a high stakes working session where real decisions were made
624
00:40:38,160 --> 00:40:41,680
and anomalies were investigated before they had a chance to compound
625
00:40:41,680 --> 00:40:43,040
into a disaster.
626
00:40:43,040 --> 00:40:47,760
Quarterly rebalancing of reserved instances and savings plans
627
00:40:47,760 --> 00:40:50,320
became a strict discipline within the organization.
628
00:40:50,320 --> 00:40:52,160
You cannot simply buy a three-year commitment
629
00:40:52,160 --> 00:40:54,080
and ignore it for the next 36 months
630
00:40:54,080 --> 00:40:55,920
while your workloads shift and evolve.
631
00:40:55,920 --> 00:40:58,240
These teams measured actual usage to understand
632
00:40:58,240 --> 00:41:00,240
which workloads were truly steady state
633
00:41:00,240 --> 00:41:03,040
and which ones were variable enough to warrant a different approach.
634
00:41:03,040 --> 00:41:06,960
Every 90 days, they adjusted their commitments based on what they had actually
635
00:41:06,960 --> 00:41:08,240
learned about their environment.
636
00:41:08,240 --> 00:41:10,240
This is continuous optimization in action
637
00:41:10,240 --> 00:41:12,560
rather than a one-time financial gamble.
638
00:41:12,560 --> 00:41:16,960
Automated license rationalization became the new baseline for managing SaaS and PASCOSTs.
639
00:41:16,960 --> 00:41:19,200
They moved away from manual audits and implemented tools
640
00:41:19,200 --> 00:41:22,800
that ran every single night to measure exactly who was using Microsoft 365
641
00:41:22,800 --> 00:41:24,160
or the Power Platform.
642
00:41:24,160 --> 00:41:26,480
These systems identified over-licensed users
643
00:41:26,480 --> 00:41:28,560
and flagged inactive applications.
644
00:41:28,560 --> 00:41:31,520
Surfacing duplicate automations that were wasting resources.
645
00:41:31,520 --> 00:41:32,880
When the data arrived each morning,
646
00:41:32,880 --> 00:41:36,000
the organization acted on it immediately by rebalancing licenses
647
00:41:36,000 --> 00:41:38,640
and deleting the apps that no longer served a purpose.
648
00:41:38,640 --> 00:41:41,120
Scheduled shutdowns for development and testing environments
649
00:41:41,120 --> 00:41:43,360
became a non-negotiable rule.
650
00:41:43,360 --> 00:41:46,160
At 6 p.m. every weekday and all day during the weekend,
651
00:41:46,160 --> 00:41:48,080
these systems went dark automatically.
652
00:41:48,080 --> 00:41:51,120
This wasn't an optional setting that a clever developer could disable
653
00:41:51,120 --> 00:41:53,680
because the infrastructure itself enforced the policy.
654
00:41:53,680 --> 00:41:57,200
These environments only came back online at 6 a.m. on Monday morning,
655
00:41:57,200 --> 00:42:01,280
which alone reclaimed 20 to 40% of the non-production budget.
656
00:42:01,280 --> 00:42:05,200
Development infrastructure simply does not need to run when no one is working
657
00:42:05,200 --> 00:42:08,320
and the only reason it ever stayed on was a lack of automation.
658
00:42:08,320 --> 00:42:12,240
Cost allocation by team served as the primary accountability mechanism
659
00:42:12,240 --> 00:42:13,600
for the entire enterprise.
660
00:42:13,600 --> 00:42:16,160
Every single resource was tagged with a cost center
661
00:42:16,160 --> 00:42:20,080
and every subscription was tied to a specific owner who was responsible for the bill.
662
00:42:20,080 --> 00:42:24,080
They implemented a chargeback model that forced teams to look at their own consumption
663
00:42:24,080 --> 00:42:26,400
rather than hiding behind a general IT budget.
664
00:42:26,400 --> 00:42:30,320
When teams finally saw the direct impact of their choices on their own bottom line,
665
00:42:30,320 --> 00:42:35,280
their behavior changed overnight because they finally understood the consequences of over-provisioning.
666
00:42:35,280 --> 00:42:38,880
Anomaly detection acted as an early warning system that fired alerts
667
00:42:38,880 --> 00:42:42,400
whenever spending deviated from the forecast by more than 10%.
668
00:42:42,400 --> 00:42:45,040
Instead of waiting for a shocking bill at the end of the month,
669
00:42:45,040 --> 00:42:48,640
they detected spikes in real-time and investigated them immediately.
670
00:42:48,640 --> 00:42:51,920
When a team's Azure spend jumped 15% in a single week
671
00:42:51,920 --> 00:42:54,880
and alert fired and the investigation began that same afternoon,
672
00:42:54,880 --> 00:42:58,000
they caught a developer who had provisioned 100 VMs for a load test
673
00:42:58,000 --> 00:43:02,000
and forgotten to turn them off, saving thousands of dollars before the damage could escalate.
674
00:43:02,000 --> 00:43:05,520
The voice of the CFO becomes very clear when you look at the results of this model.
675
00:43:05,520 --> 00:43:08,800
They stopped guessing about the future and started measuring the present,
676
00:43:08,800 --> 00:43:12,400
which allowed them to forecast with a level of confidence they never had before.
677
00:43:12,400 --> 00:43:15,680
The enterprise architect will tell you that they stopped reacting to fires
678
00:43:15,680 --> 00:43:17,920
and started designing systems that couldn't burn.
679
00:43:17,920 --> 00:43:19,680
They built efficiency into the platform
680
00:43:19,680 --> 00:43:22,720
and made the default configuration the only configuration.
681
00:43:22,720 --> 00:43:25,840
As a cynical architect might put it, they stopped assuming the cloud was cheaper
682
00:43:25,840 --> 00:43:27,520
and started engineering it to be.
683
00:43:27,520 --> 00:43:30,800
The actual outcome for enterprises that commit to this operating model
684
00:43:30,800 --> 00:43:32,880
is remarkably consistent across industries.
685
00:43:32,880 --> 00:43:38,400
They see sustained cost reductions of 25% to 35% that last for 18 months and well beyond.
686
00:43:38,400 --> 00:43:41,440
These aren't one-time wins, but permanent shifts in the cost curve
687
00:43:41,440 --> 00:43:43,760
because the operating model enforces the discipline.
688
00:43:43,760 --> 00:43:46,640
Every month the board meets, every quarter the commitments are balanced
689
00:43:46,640 --> 00:43:49,200
and every night the automation hunts for waste.
690
00:43:49,200 --> 00:43:50,720
The results aren't a matter of luck.
691
00:43:50,720 --> 00:43:53,440
They are the inevitable consequence of a relentless process.
692
00:43:53,440 --> 00:43:58,560
This architectural insight is what separates the organizations that save millions
693
00:43:58,560 --> 00:44:00,320
from the ones that save nothing at all.
694
00:44:00,320 --> 00:44:03,520
Cost optimization is not a financial problem to be solved by accountants
695
00:44:03,520 --> 00:44:06,000
but an operational discipline to be mastered by engineers.
696
00:44:06,000 --> 00:44:10,640
It is not a task you finish, but a rhythm that you build into the very heart of the business.
697
00:44:10,640 --> 00:44:14,640
When you make efficiency, structural and non-negotiable the savings follow naturally.
698
00:44:14,640 --> 00:44:16,240
You aren't just being clever with your money,
699
00:44:16,240 --> 00:44:20,240
you are being disciplined with your design and engineering determinism into the system itself.
700
00:44:20,640 --> 00:44:23,520
The hidden architecture, governance as a control plane,
701
00:44:23,520 --> 00:44:27,280
most enterprises treat governance like attacks or a layer of compliance overhead
702
00:44:27,280 --> 00:44:29,520
that exists only to satisfy auditors.
703
00:44:29,520 --> 00:44:33,280
They view it as a necessary evil that inevitably slows down innovation
704
00:44:33,280 --> 00:44:34,480
and gets in the way of speed.
705
00:44:34,480 --> 00:44:38,560
The organizations that actually saved millions look at the problem through a different lens.
706
00:44:38,560 --> 00:44:41,760
They see governance as the foundation of determinism,
707
00:44:41,760 --> 00:44:46,000
acting as the control plane that makes every other technical success possible.
708
00:44:46,000 --> 00:44:50,640
As your policy is not an optional suggestion or a piece of friendly advice for your teams,
709
00:44:50,640 --> 00:44:54,400
it functions as a set of mandatory guardrails applied to every single subscription
710
00:44:54,400 --> 00:44:56,880
to ensure architectural intent is actually met.
711
00:44:56,880 --> 00:45:00,880
If a developer tries to spin up a resource that violates a specific policy,
712
00:45:00,880 --> 00:45:03,040
the system rejects that request immediately.
713
00:45:03,040 --> 00:45:06,000
This failure doesn't happen weeks later during a manual audit
714
00:45:06,000 --> 00:45:07,680
but right at the moment of creation.
715
00:45:07,680 --> 00:45:09,920
This isn't friction for the sake of being difficult
716
00:45:09,920 --> 00:45:14,080
but rather a way to enforce architecture instantly instead of trying to retrofit it
717
00:45:14,080 --> 00:45:19,440
months down the line. Your tagging strategy requires that same level of rigid discipline to be effective.
718
00:45:19,440 --> 00:45:24,080
Every resource must carry data for cost centers, environments, owners and applications
719
00:45:24,080 --> 00:45:27,120
or the system simply won't allow the provisioning to complete.
720
00:45:27,120 --> 00:45:31,040
This forces a specific type of discipline at the start of the life cycle,
721
00:45:31,040 --> 00:45:34,960
making teams think about what they are building before they actually hit deploy.
722
00:45:34,960 --> 00:45:38,720
When you force clarity regarding ownership and purpose at the beginning,
723
00:45:38,720 --> 00:45:43,520
that precision cascades into much better financial decisions further downstream.
724
00:45:43,520 --> 00:45:48,240
Managed environments within the power platform operate under the same architectural laws.
725
00:45:48,240 --> 00:45:51,920
By enforcing strict boundaries between production, sandbox and personal spaces
726
00:45:51,920 --> 00:45:55,120
at the platform layer, you eliminate the risk of accidental logic leaks.
727
00:45:55,120 --> 00:45:58,240
You cannot deploy critical business code to a personal environment
728
00:45:58,240 --> 00:46:01,120
and you cannot test new features in a live production setting.
729
00:46:01,120 --> 00:46:04,880
These boundaries are maintained by the system itself rather than by policy documents
730
00:46:04,880 --> 00:46:06,480
that people usually ignore.
731
00:46:06,480 --> 00:46:08,800
Technical controls make violations impossible
732
00:46:08,800 --> 00:46:11,680
which is the only way to truly manage a distributed environment.
733
00:46:11,680 --> 00:46:14,800
Conditional access determines exactly who can touch the environment
734
00:46:14,800 --> 00:46:16,720
and under what specific circumstances.
735
00:46:16,720 --> 00:46:18,720
It dictates who can provision resources,
736
00:46:18,720 --> 00:46:23,120
which networks they must use and what level of device health is required for entry.
737
00:46:23,120 --> 00:46:26,320
These are not optional security features you turn on when you feel like it,
738
00:46:26,320 --> 00:46:30,080
but mandatory baselines that every production subscription must inherit.
739
00:46:30,080 --> 00:46:33,280
If a team wants to change these defaults, they have to justify the risk
740
00:46:33,280 --> 00:46:35,120
and get formal approval first.
741
00:46:35,120 --> 00:46:37,280
The system stays locked down by default,
742
00:46:37,280 --> 00:46:41,040
meaning any deviation requires a conscious, documented decision.
743
00:46:41,040 --> 00:46:44,560
Roll-based access control is how you enforce the principle of least privilege
744
00:46:44,560 --> 00:46:46,400
across the entire organization.
745
00:46:46,400 --> 00:46:48,960
Not every user needs admin rights to every service,
746
00:46:48,960 --> 00:46:52,880
so you grant access only to the specific subscriptions required for a job.
747
00:46:52,880 --> 00:46:55,280
Developers stay in dev environments,
748
00:46:55,280 --> 00:47:00,160
operations handles production and finance gets restricted to the cost data they actually need.
749
00:47:00,160 --> 00:47:02,560
The separation of duties is baked into the platform layer
750
00:47:02,560 --> 00:47:05,680
so the system stops unauthorized access attempts automatically.
751
00:47:05,680 --> 00:47:07,920
This isn't a matter of trusting your employees,
752
00:47:07,920 --> 00:47:12,000
but an architectural choice to make doing the wrong thing as difficult as possible.
753
00:47:12,000 --> 00:47:17,120
Consider a real case study from a large enterprise that finally enforced mandatory tagging at scale.
754
00:47:17,120 --> 00:47:21,440
They manage to save eight hours every single week on cost allocation tasks alone,
755
00:47:21,440 --> 00:47:24,400
simply because their data was finally consistent and auditable.
756
00:47:24,400 --> 00:47:27,120
Because the system rejected untagged resources,
757
00:47:27,120 --> 00:47:32,240
they never had to waste time hunting down which department owned a specific set of orphaned VMs.
758
00:47:32,240 --> 00:47:34,320
The tags provided the answers automatically,
759
00:47:34,320 --> 00:47:37,760
creating an operational efficiency that compounded into massive savings
760
00:47:37,760 --> 00:47:42,320
month after month. Another organization implemented managed environments for their power platform
761
00:47:42,320 --> 00:47:45,920
and saw support tickets dropped by 40 percent almost immediately.
762
00:47:45,920 --> 00:47:48,400
This didn't happen because the software magically got better,
763
00:47:48,400 --> 00:47:53,440
but because governance stopped the chaotic sprawl that was generating those tickets in the first place.
764
00:47:53,440 --> 00:47:56,800
They no longer dealt with orphaned apps that required constant maintenance
765
00:47:56,800 --> 00:48:00,000
or duplicate automations that created massive data confusion.
766
00:48:00,000 --> 00:48:04,960
Governance created a level of clarity that naturally reduced the overhead required to keep the lights on.
767
00:48:04,960 --> 00:48:09,120
There is a counterintuitive truth that separates the successful organizations from the ones that
768
00:48:09,120 --> 00:48:14,720
are constantly struggling. More governance actually leads to less friction once the system is fully implemented.
769
00:48:14,720 --> 00:48:18,560
Consistency eliminates the exceptions where waste likes to hide.
770
00:48:18,560 --> 00:48:20,880
And when every subscription follows the same baseline,
771
00:48:20,880 --> 00:48:23,040
deviations become instantly visible.
772
00:48:23,040 --> 00:48:25,600
When every team operates under the same set of rules,
773
00:48:25,600 --> 00:48:29,600
waste becomes obvious and optimization finally becomes a realistic goal.
774
00:48:29,600 --> 00:48:33,920
The cynical architect's final law is that governance is not the enemy of agility.
775
00:48:33,920 --> 00:48:36,880
It is actually the only foundation for predictable agility,
776
00:48:36,880 --> 00:48:40,240
allowing you to move fast without the fear of a total system collapse.
777
00:48:40,240 --> 00:48:43,120
You can innovate and experiment as rapidly as you want.
778
00:48:43,120 --> 00:48:47,040
Provided you stay within a framework that prevents catastrophic financial mistakes.
779
00:48:47,040 --> 00:48:51,040
This structure prevents the kind of unmanaged chaos that typically leaves millions of dollars
780
00:48:51,040 --> 00:48:52,080
on the table every year.
781
00:48:52,080 --> 00:48:56,720
This is the hidden architecture that most leadership teams completely missed during their cloud migration.
782
00:48:56,720 --> 00:48:58,480
While they see governance as a constraint,
783
00:48:58,480 --> 00:49:02,480
the organizations that save millions see it as a foundational control plane,
784
00:49:02,480 --> 00:49:07,440
you must build the governance model first and make it entirely non-negotiable if you want to see real results.
785
00:49:07,440 --> 00:49:09,680
Once the rules are enforced by the system,
786
00:49:09,680 --> 00:49:14,720
your costs, reliability and speed will all improve because of the guardrails, not despite them.
787
00:49:14,720 --> 00:49:18,480
The Finops discipline - metrics that matter.
788
00:49:18,480 --> 00:49:21,520
You cannot optimize a system that you aren't accurately measuring,
789
00:49:21,520 --> 00:49:24,560
yet most enterprises continue to track the wrong data points.
790
00:49:24,560 --> 00:49:28,160
They watch total cloud spend and month over month growth,
791
00:49:28,160 --> 00:49:31,840
but these numbers don't reveal if the environment is actually getting more efficient.
792
00:49:31,840 --> 00:49:36,000
These are vanity metrics that make you feel like you're in control while the architecture is actually
793
00:49:36,000 --> 00:49:37,200
drifting toward entropy.
794
00:49:37,200 --> 00:49:41,680
The organizations that reclaimed millions of dollars focused on metrics that force them to confront
795
00:49:41,680 --> 00:49:43,120
an uncomfortable reality.
796
00:49:43,120 --> 00:49:48,880
Reserved instance and savings plan coverage is the first metric that truly defines your financial discipline.
797
00:49:48,880 --> 00:49:53,280
You need to know exactly what percentage of your compute spend is covered by long-term commitments
798
00:49:53,280 --> 00:49:55,040
rather than on-demand pricing.
799
00:49:55,040 --> 00:50:00,320
A healthy target sits between 65 and 75 percent because anything lower means you are paying full
800
00:50:00,320 --> 00:50:01,760
price for steady workloads.
801
00:50:01,760 --> 00:50:05,680
If you go too high, you risk paying for idle capacity you don't actually need.
802
00:50:05,680 --> 00:50:09,840
So this metric forces a necessary conversation about workload variability.
803
00:50:09,840 --> 00:50:13,680
Cost per workload is the second metric you need to monitor with extreme precision.
804
00:50:13,680 --> 00:50:16,080
Total cost is a useless number without context,
805
00:50:16,080 --> 00:50:20,400
so you must track spend per transaction, per user or per compute hour.
806
00:50:20,400 --> 00:50:22,560
If your cost per transaction starts climbing,
807
00:50:22,560 --> 00:50:26,800
it serves as an immediate warning that your architectural efficiency is beginning to degrade.
808
00:50:26,800 --> 00:50:31,680
This metric creates a level of accountability that makes it impossible for teams to hide wasteful
809
00:50:31,680 --> 00:50:34,560
habits behind the excuse of overall company growth.
810
00:50:34,560 --> 00:50:37,200
Idl resource percentage is the third metric,
811
00:50:37,200 --> 00:50:41,120
and it is perhaps the most brutal indicator of a failed provisioning strategy.
812
00:50:41,120 --> 00:50:44,800
You need to identify what percentage of your resources are running at less than 5 percent
813
00:50:44,800 --> 00:50:46,320
utilization at any given time.
814
00:50:46,320 --> 00:50:49,920
If that number stays above 5 percent, you have a fundamental problem with how your
815
00:50:49,920 --> 00:50:51,920
teams are right-sizing their environments.
816
00:50:51,920 --> 00:50:55,600
You can't argue with a VM that is sitting at 2 percent CPU usage,
817
00:50:55,600 --> 00:50:59,200
and this metric makes that waste undeniable to everyone involved.
818
00:50:59,200 --> 00:51:04,160
Cost variance versus your forecast is the fourth metric that determines if you actually understand
819
00:51:04,160 --> 00:51:05,120
your own environment.
820
00:51:05,120 --> 00:51:08,400
If your forecast accuracy is consistently below 80 percent,
821
00:51:08,400 --> 00:51:11,920
it means your internal model is broken and you're essentially flying blind.
822
00:51:11,920 --> 00:51:15,600
High accuracy allows you to budget with certainty and make data-driven decisions
823
00:51:15,600 --> 00:51:18,160
rather than relying on a series of educated guesses.
824
00:51:18,160 --> 00:51:20,080
When you can't predict what you'll spend next month,
825
00:51:20,080 --> 00:51:23,280
you don't have enough visibility to claim you are managing the platform.
826
00:51:23,280 --> 00:51:28,240
License utilization is the fifth metric, and it's where most companies discover they are massively
827
00:51:28,240 --> 00:51:32,480
overspending on SaaS features. You might have 12,000 high tier licenses active,
828
00:51:32,480 --> 00:51:36,000
but if only a fraction of those users touch the advanced security features,
829
00:51:36,000 --> 00:51:37,600
you are throwing money away.
830
00:51:37,600 --> 00:51:42,080
This metric forces a right-sizing conversation that challenges the lazy habit of buying universal
831
00:51:42,080 --> 00:51:46,720
coverage for every employee. It makes it clear that paying for features that nobody uses is a
832
00:51:46,720 --> 00:51:51,840
direct hit to the bottom line. Shatter workload ratio is the final metric, revealing the true
833
00:51:51,840 --> 00:51:55,760
scale of your governance problem. You need to know what percentage of your workloads are running
834
00:51:55,760 --> 00:51:58,800
outside of your managed, governed, and accounted for environments.
835
00:51:58,800 --> 00:52:02,480
If this ratio climbs above 10 percent, you have lost control of the architecture,
836
00:52:02,480 --> 00:52:05,520
and future security or cost problems are now inevitable.
837
00:52:05,520 --> 00:52:10,160
This is a leading indicator of disaster, predicting exactly where your next compliance or budget
838
00:52:10,160 --> 00:52:14,800
failure will originate. One enterprise tracked these six metrics rigorously for half a year,
839
00:52:14,800 --> 00:52:18,800
and saw their R.I. coverage jump from 38 percent to 72 percent.
840
00:52:18,800 --> 00:52:23,520
During that same period, their cost per transaction dropped by 18 percent, while their idle resource
841
00:52:23,520 --> 00:52:28,320
percentage plummeted to nearly nothing. Their forecast accuracy improved so much that they could plan
842
00:52:28,320 --> 00:52:33,040
their yearly budget with 4 percent variance instead of 18. These weren't lucky breaks or one-time
843
00:52:33,040 --> 00:52:37,680
wins, but the result of metrics forcing a culture of continuous technical discipline.
844
00:52:37,680 --> 00:52:42,400
The cynical architect knows that metrics drive behavior, so you must choose the ones that make
845
00:52:42,400 --> 00:52:46,640
optimization an inevitable outcome. Don't settle for data that makes the department look good,
846
00:52:46,640 --> 00:52:51,040
or hides the reality of your architectural erosion. You need to choose metrics that make you
847
00:52:51,040 --> 00:52:55,840
uncomfortable enough to actually change how the system is configured. Optimization is the only
848
00:52:55,840 --> 00:53:00,400
path to reclaiming millions, and it's the only way to turn the cloud into a genuine competitive
849
00:53:00,400 --> 00:53:06,080
advantage. The inevitable enterprise, why this becomes architectural law? This is the thesis that
850
00:53:06,080 --> 00:53:10,080
ties everything together, because waste is not a bug in your environment. It is a feature of
851
00:53:10,080 --> 00:53:15,120
unmanaged systems. You are not looking at a failure of individual teams, or a series of bad decisions
852
00:53:15,120 --> 00:53:20,240
by isolated leaders, but rather a mathematical inevitability. Unmanaged cloud mathematically
853
00:53:20,240 --> 00:53:25,840
produces waste. This is not a matter of opinion. It is a law of physics. Permission without policy
854
00:53:25,840 --> 00:53:30,240
always scales to chaos. When you give people the ability to provision resources, they will provision
855
00:53:30,240 --> 00:53:34,000
them. When you give them the ability to create applications or experiment with new services,
856
00:53:34,000 --> 00:53:38,560
they will do exactly that. Without a system that actually says no, and without someone enforcing
857
00:53:38,560 --> 00:53:42,560
boundaries or measuring what is being used versus what is being wasted, the default outcome is
858
00:53:42,560 --> 00:53:46,880
sprawl. You end up with a bill that nobody understands and nobody can control, provisioning without
859
00:53:46,880 --> 00:53:51,920
deprovisioning always scales to debt. While you can create infrastructure in minutes, destroying it
860
00:53:51,920 --> 00:53:56,880
requires governance, decision making, and someone willing to state that a resource is no longer needed.
861
00:53:56,880 --> 00:54:01,680
Because that rarely happens, infrastructure stays, workloads, linger, and applications run long
862
00:54:01,680 --> 00:54:06,160
after their purpose has been served. The organization accumulates technical debt like sediment layer after
863
00:54:06,160 --> 00:54:10,960
layer until the environment becomes so complex that nobody understands what is actually running or why.
864
00:54:12,000 --> 00:54:16,320
Licensing without utilization measurement always scales to overspend. Most organizations license
865
00:54:16,320 --> 00:54:20,960
broadly because it feels like the safe choice to ensure universal coverage and maximum capability.
866
00:54:20,960 --> 00:54:24,480
However, if you do not measure whether people actually need what they are licensed for,
867
00:54:24,480 --> 00:54:29,120
you lose sight of the gap between what you paid for and what is actually being consumed.
868
00:54:29,120 --> 00:54:33,920
The overspend compounds with every license renewal fueled by the assumption that premium is always
869
00:54:33,920 --> 00:54:38,400
better even when the data shows that most users never touch those features. Experimentation without
870
00:54:38,400 --> 00:54:43,360
governance always scales to shadow IT. Teams want to innovate and build solutions to their problems,
871
00:54:43,360 --> 00:54:47,920
so they provision infrastructure and create integrations outside of formal processes. They do
872
00:54:47,920 --> 00:54:53,040
this because formal processes are slow, they require approval, and they generally get in the way
873
00:54:53,040 --> 00:54:58,000
of moving fast. This shadow it grows unmeasured and unaccounted for until you eventually realize that
874
00:54:58,000 --> 00:55:02,560
half of your infrastructure is running entirely outside of your control. The cynical architect sees
875
00:55:02,560 --> 00:55:06,720
this with absolute certainty. You do not have a cost problem, you have an architecture problem.
876
00:55:06,720 --> 00:55:11,120
Once you fix the architecture, the cost fixes itself. We have seen organizations stop trying to
877
00:55:11,120 --> 00:55:15,680
negotiate discounts and start engineering efficiency instead. There is a real pattern among every
878
00:55:15,680 --> 00:55:20,480
enterprise that reduced spend by 25% or more. They did not achieve those results by getting
879
00:55:20,480 --> 00:55:24,880
better rates from Microsoft or by negotiating harder at the table. They did it by implementing
880
00:55:24,880 --> 00:55:29,600
governance first. Not discounts, not optimization and not tools. Governance was the foundation and
881
00:55:29,600 --> 00:55:33,920
everything else followed. When an enterprise sustained savings for 18 months or longer,
882
00:55:33,920 --> 00:55:38,480
it is because they built a FinOps discipline rather than a one-time cost-cutting project.
883
00:55:38,480 --> 00:55:43,280
This requires a relentless rhythm of monthly reviews, quarterly rebalancing, and continuous
884
00:55:43,280 --> 00:55:47,840
measurement. When you combine that with automated enforcement, the results become inevitable.
885
00:55:47,840 --> 00:55:52,640
Enterprises that scale to multi-region and multi-work load environments without losing control
886
00:55:52,640 --> 00:55:57,360
rely on policy-driven provisioning. They do not use ad hoc or approval-based methods. Every new
887
00:55:57,360 --> 00:56:01,360
subscription inherits the baseline, every new resource follows the pattern, and every new team
888
00:56:01,360 --> 00:56:05,520
operates under the same rules. This creates consistency and standardization at scale.
889
00:56:05,520 --> 00:56:09,360
The inevitable outcome is simple. Organizations that engineer for determinism
890
00:56:09,360 --> 00:56:14,000
do not need to negotiate discounts because they engineer waste out of the system. They make it harder
891
00:56:14,000 --> 00:56:17,680
to waste money than to optimize it, ensuring the default configuration is always the right
892
00:56:17,680 --> 00:56:22,720
configuration. When you make efficiency structural instead of aspirational, low and predictable
893
00:56:22,720 --> 00:56:26,880
costs become the new law of the land. This architectural law separates the organizations that
894
00:56:26,880 --> 00:56:30,880
saved millions from those that are still struggling. It is not about being clever or finding
895
00:56:30,880 --> 00:56:35,440
hidden discounts. It is about being disciplined. You must engineer the system to prevent waste,
896
00:56:35,440 --> 00:56:40,160
rather than reacting to it with firefighting. When you accept this architectural inevitability,
897
00:56:40,160 --> 00:56:45,200
everything changes. The co-pilot factor, AI governance as the next frontier. Everything we have
898
00:56:45,200 --> 00:56:50,560
discussed so far applies to traditional infrastructure like reserved instances, idle VMs, and power
899
00:56:50,560 --> 00:56:55,040
platforms. These are problems that have existed for years, and while organizations have not managed
900
00:56:55,040 --> 00:56:59,280
them perfectly, they have at least learned how they work. Co-pilot and AI changed the equation
901
00:56:59,280 --> 00:57:03,840
entirely. They change it in ways that most organizations have not yet grasped, and the cost implications
902
00:57:03,840 --> 00:57:09,440
are orders of magnitude more severe. AI workloads are fundamentally different from traditional compute,
903
00:57:09,440 --> 00:57:14,720
because they are explosive rather than steady state. A single co-pilot user can generate thousands
904
00:57:14,720 --> 00:57:20,400
of tokens in one composition, and a team of users can easily generate millions of tokens in a single
905
00:57:20,400 --> 00:57:25,280
day. Since tokens cost real measurable money, the bill becomes incomprehensible if you do not
906
00:57:25,280 --> 00:57:30,240
govern and measure that usage. One enterprise deployed co-pilot broadly without any quotas,
907
00:57:30,240 --> 00:57:35,760
controls, or visibility into token usage. Teams began spinning up a "jure open" AI endpoints
908
00:57:35,760 --> 00:57:40,640
without approval or capacity planning, and the infrastructure tax hit the bottom line immediately.
909
00:57:40,640 --> 00:57:45,360
Gateway costs, always on compute, and safety filtering, were all billed separately from token
910
00:57:45,360 --> 00:57:51,520
pricing. A FinTech team's AI experiments cost $340,000 per month before governance was finally
911
00:57:51,520 --> 00:57:56,800
implemented. That was the price for a team of only 12 people. The intervention for AI is different
912
00:57:56,800 --> 00:58:01,680
from traditional cost optimization. You cannot simply shut down idle AI workloads or apply reserved
913
00:58:01,680 --> 00:58:06,720
instances and hope for the best. AI requires a different discipline that starts with data readiness
914
00:58:06,720 --> 00:58:11,680
assessments and the enforcement of sensitivity labeling. You must clean up SharePoint, remove
915
00:58:11,680 --> 00:58:16,640
often sites, and enforce retention policies before moving forward. If you deploy co-pilot into an
916
00:58:16,640 --> 00:58:21,680
environment where data governance is merely aspirational, the AI will amplify every failure and surface
917
00:58:21,680 --> 00:58:26,160
information that should have been deleted years ago. The same enterprise eventually implemented
918
00:58:26,160 --> 00:58:30,480
sensitivity labeling first and co-pilot second, they cleaned up SharePoint and implemented
919
00:58:30,480 --> 00:58:34,880
conditional access so that co-pilot was only accessible from managed devices. Instead of a
920
00:58:34,880 --> 00:58:40,160
company-wide rollout, they started with 400 power users to measure adoption and ROI. They allocated
921
00:58:40,160 --> 00:58:45,280
licenses by roll rather than seat count and enforced hard limits on tokens per user and per model.
922
00:58:45,280 --> 00:58:49,920
The infrastructure tax remained, but it was finally predictable and controlled. The outcome was
923
00:58:49,920 --> 00:58:57,040
dramatic for that FinTech team. Their monthly spend dropped from $340,000 to $68,000 representing an 80%
924
00:58:57,040 --> 00:59:01,840
cost reduction. They did not achieve this by cutting features, but by implementing governance
925
00:59:01,840 --> 00:59:06,560
and controlling who could access specific models. The governance did not reduce their capability,
926
00:59:06,560 --> 00:59:12,080
it simply removed the waste. The lesson here is both architectural and urgent. AI governance is the
927
00:59:12,080 --> 00:59:17,120
difference between innovation and bankruptcy. You cannot deploy co-pilot at scale or let teams spin
928
00:59:17,120 --> 00:59:22,080
up AI endpoints without approval and strict controls. The cost and risk structures are entirely different
929
00:59:22,080 --> 00:59:26,160
from what you are used to and organizations that ignore this will only discover the truth
930
00:59:26,160 --> 00:59:31,600
when their bills arrive. The cynical architects observation is blunt. You do not have a co-pilot
931
00:59:31,600 --> 00:59:36,160
adoption problem. You have a data governance problem. Furthermore, you do not have a data governance
932
00:59:36,160 --> 00:59:40,640
problem. You have an architecture problem. If your architecture does not make it hard to misuse
933
00:59:40,640 --> 00:59:45,520
data or visible when data is accessed inappropriately, co-pilot will only make the situation worse.
934
00:59:45,520 --> 00:59:49,600
This is the frontier where the next wave of waste will happen. Organizations that do not
935
00:59:49,600 --> 00:59:54,320
govern early will discover they have spent millions on AI experiments that should have been shut
936
00:59:54,320 --> 00:59:58,800
down months ago. The organizations that reclaim those millions are the ones that implement governance
937
00:59:58,800 --> 01:00:03,360
before they scale. Data readiness comes first followed by co-pilot measurement and discipline,
938
01:00:03,360 --> 01:00:08,880
that is the only pattern that actually works. The consolidation imperative from sprawl to integration.
939
01:00:08,880 --> 01:00:14,240
The final piece of this architectural puzzle is consolidation and I say that because every enterprise
940
01:00:14,240 --> 01:00:18,640
that actually saved millions followed this exact path, they didn't do it because consolidation is
941
01:00:18,640 --> 01:00:24,000
some kind of moral virtue, but because fragmentation is objectively expensive. SAS sprawl is the
942
01:00:24,000 --> 01:00:28,000
enemy here, not because the software itself is flawed, but because the resulting fragmentation
943
01:00:28,000 --> 01:00:32,240
creates a massive tax on the organization. When you have 50 different tools, you don't actually
944
01:00:32,240 --> 01:00:36,720
have 50 solutions. Instead you have one fundamental problem that you are paying to repeat 50 times
945
01:00:36,720 --> 01:00:41,360
over. You are paying for data silos, integration overhead and duplicate functionality, while the
946
01:00:41,360 --> 01:00:46,560
licensing complexity and support burden compound with every single tool you add to the environment.
947
01:00:46,560 --> 01:00:52,080
Power platform consolidation is your most direct lever for change, allowing you to replace 50
948
01:00:52,080 --> 01:00:56,640
niche SAS tools with a single unified low-code ecosystem. This isn't about following a trend,
949
01:00:56,640 --> 01:01:01,760
but about the architectural reality that consolidation reduces complexity by removing unnecessary
950
01:01:01,760 --> 01:01:06,080
moving parts. I watched one enterprise take 47 different power platform environments and
951
01:01:06,080 --> 01:01:11,200
collapse them down into just 12, and they did this without deleting a single necessary capability.
952
01:01:11,200 --> 01:01:16,160
They simply eliminated the duplicate environments where the same logic was being rebuilt over and
953
01:01:16,160 --> 01:01:22,640
over, which allowed them to prune 4800 power apps down to 1200 active ones. They didn't lose
954
01:01:22,640 --> 01:01:27,040
functionality, they simply identified that 62% of those apps were never even opened after they
955
01:01:27,040 --> 01:01:32,480
were deployed and removed the waste. The financial impact of this shift was immediate, resulting in a
956
01:01:32,480 --> 01:01:38,000
30 to 50% reduction in both SAS and power platform licensing costs. These savings didn't come from
957
01:01:38,000 --> 01:01:43,280
aggressive contract negotiations, but from the simple realization that they didn't need 50 tools
958
01:01:43,280 --> 01:01:47,360
when one correctly configured platform would suffice. The operational impact was just as
959
01:01:47,360 --> 01:01:51,360
significant because it provided a single pane of glass for governance and audit trails that
960
01:01:51,360 --> 01:01:56,400
actually made sense to a human reviewer. Compliance became enforceable rather than aspirational,
961
01:01:56,400 --> 01:02:00,560
and data flows became visible instead of being scattered across a dozen disparate systems.
962
01:02:01,120 --> 01:02:06,400
When you choose to consolidate, you gain visibility. And in this architecture, visibility is the only
963
01:02:06,400 --> 01:02:11,680
thing that truly enables control. Microsoft 365 consolidation follows the same logical pattern,
964
01:02:11,680 --> 01:02:16,080
starting with the decision to stop handing out e5 licenses to everyone and instead licensing
965
01:02:16,080 --> 01:02:20,720
by specific role. You have to eliminate the redundant add-ons that provide no value to the average
966
01:02:20,720 --> 01:02:27,120
user. I saw an organization with 12,000 over-licensed seats, rebalance their entire tenant to a mixed
967
01:02:27,120 --> 01:02:33,600
model that used e5 for security dependent roles, e3 for core knowledge workers, and f3 for the front line.
968
01:02:33,600 --> 01:02:38,080
Their security posture actually improved because the organization finally understood which
969
01:02:38,080 --> 01:02:43,200
users required which specific features to do their jobs safely. This moved lead to a cost reduction
970
01:02:43,200 --> 01:02:48,720
of 15 to 28%, which put $1.2 million back in the budget annually through a permanent right-sized
971
01:02:48,720 --> 01:02:54,000
model. Azure consolidation is a matter of architectural enforcement, requiring you to mandate
972
01:02:54,000 --> 01:02:58,800
landing zones and eliminate duplicate environments across the board. You must standardize on a
973
01:02:58,800 --> 01:03:02,880
hub-spoke architecture to prevent the sprawl that naturally occurs when teams are left to their
974
01:03:02,880 --> 01:03:08,080
own devices. One enterprise I worked with had redundant infrastructure spread across five
975
01:03:08,080 --> 01:03:12,320
different regions, but they consolidated everything into a single reference implementation.
976
01:03:12,320 --> 01:03:18,880
This resulted in a 12 to 20% reduction in infrastructure costs, saving $340,000 every year.
977
01:03:18,880 --> 01:03:23,760
The real benefit was operational, as provisioning time dropped from three weeks to just three days
978
01:03:23,760 --> 01:03:28,320
because consistency and predictability enabled the system to scale. The pattern across these
979
01:03:28,320 --> 01:03:32,880
efforts is remarkably consistent, and it reveals that you don't consolidate just because you want
980
01:03:32,880 --> 01:03:37,920
a shorter list of vendors. You consolidate because fragmentation is a hidden tax, and duplicate
981
01:03:37,920 --> 01:03:43,200
functionality will always cost more than a unified system. Data silos create friction that slows down
982
01:03:43,200 --> 01:03:47,520
every process and every new tool you add to the stack multiplies your governance burden.
983
01:03:47,520 --> 01:03:52,320
Integration overhead compounds as you scale making the licensing complexity of 50 tools far
984
01:03:52,320 --> 01:03:57,120
more expensive than managing one platform that has been configured correctly from the start.
985
01:03:57,120 --> 01:04:01,760
From the perspective of a cynical architect, consolidation is simply a law of the system,
986
01:04:01,760 --> 01:04:07,840
and it is never about doing less for the business. It is about doing more with a unified architecture
987
01:04:07,840 --> 01:04:11,840
that provides the efficiency and visibility you need to actually govern the environment. When
988
01:04:11,840 --> 01:04:16,080
you consolidate you don't lose capability. You gain the ability to measure and optimize the
989
01:04:16,080 --> 01:04:20,560
resources you are actually using. The organizations that consolidated most aggressively were also the
990
01:04:20,560 --> 01:04:24,720
ones that manage to innovate the fastest. This didn't happen despite the consolidation, but because
991
01:04:24,720 --> 01:04:29,280
of it as a unified architecture provides the foundation of confidence needed to move at scale.
992
01:04:29,280 --> 01:04:33,680
This is the final architectural pattern that separates the organizations that saved millions from
993
01:04:33,680 --> 01:04:37,920
the ones that are still struggling to keep the lights on. They chose to consolidate their stack
994
01:04:37,920 --> 01:04:42,240
and eliminate the fragmentation that was hiding their waste. They unified their platforms,
995
01:04:42,240 --> 01:04:46,720
standardized their implementations, and enforced their architecture with a level of discipline that
996
01:04:46,720 --> 01:04:51,680
most companies lack. When they made consolidation a structural requirement instead of a vague goal,
997
01:04:51,680 --> 01:04:56,400
their costs became structural and predictable as well. This is consolidation as an architectural
998
01:04:56,400 --> 01:05:00,960
inevitability and it is the final lever where the last few millions are usually hiding.
999
01:05:00,960 --> 01:05:07,120
The playbook, what decision-makers should do Monday morning? Theory is interesting for a white paper,
1000
01:05:07,120 --> 01:05:11,120
but you are here because you need actionable architecture that actually works in a production
1001
01:05:11,120 --> 01:05:16,080
environment. This is the playbook that separates the organizations that reclaimed millions from the ones
1002
01:05:16,080 --> 01:05:20,240
that are still sitting in meetings talking about it. Your first priority must be establishing governance
1003
01:05:20,240 --> 01:05:24,720
before you sign off on any new procurement because you cannot optimize a system you don't actually
1004
01:05:24,720 --> 01:05:29,760
govern. This isn't a friendly suggestion. It is an architectural law that you must follow before
1005
01:05:29,760 --> 01:05:34,400
you negotiate another discount or implement another tool. You have to govern what you already have
1006
01:05:34,400 --> 01:05:39,440
before you can justify adding anything new to the stack. The first step is a forensic audit of your
1007
01:05:39,440 --> 01:05:45,040
current state covering every resource, every license and every permission currently active in your tenant.
1008
01:05:45,040 --> 01:05:50,480
This isn't a casual inventory but a deep dive into what is actually running, what is actually licensed
1009
01:05:50,480 --> 01:05:55,440
and what is actually being used by your staff. This process is unglamorous and takes a significant
1010
01:05:55,440 --> 01:06:00,400
amount of time but it is a non-negotiable foundation for everything else. You cannot build a governance
1011
01:06:00,400 --> 01:06:04,320
model on a foundation of ignorance so you have to know exactly what you are trying to govern.
1012
01:06:04,320 --> 01:06:08,720
Next you must implement a mandatory tagging strategy that includes the cost center,
1013
01:06:08,720 --> 01:06:14,000
environment, owner and data classification for every single resource. If a user tries to create a
1014
01:06:14,000 --> 01:06:18,080
resource without these tags the system must be configured so that the request fails immediately.
1015
01:06:18,080 --> 01:06:23,680
You have to make this structural and non-negotiable because the tagging strategy is the only way
1016
01:06:23,680 --> 01:06:28,480
to achieve accurate cost allocation. Without these tags you can't answer basic questions about which
1017
01:06:28,480 --> 01:06:33,840
team is spending money or which environment is consuming resources unnecessarily. These tags provide
1018
01:06:33,840 --> 01:06:38,400
the answers but only if they are enforced at the platform layer without exception. Once the tags
1019
01:06:38,400 --> 01:06:43,600
are in place you have to enforce Azure policy by setting up mandatory guardrails on every subscription
1020
01:06:43,600 --> 01:06:48,000
in your environment. Start with the basics by requiring encryption and manage discs and then
1021
01:06:48,000 --> 01:06:52,720
restrict resource types to specific approved regions. You are building the policies that enforce
1022
01:06:52,720 --> 01:06:58,400
your architecture and you must make them reject any request that violates these rules in real time.
1023
01:06:58,400 --> 01:07:02,560
This creates friction for a specific purpose as it prevents the kind of waste that occurs when
1024
01:07:02,560 --> 01:07:07,840
people deploy resources outside of your established standards. Finally you need to implement
1025
01:07:07,840 --> 01:07:13,120
managed environments to create strict boundaries between production, sandbox and personal development
1026
01:07:13,120 --> 01:07:18,000
areas. In the power platform and Azure alike these boundaries must be enforced at the platform layer
1027
01:07:18,000 --> 01:07:23,360
so that no one can accidentally deploy critical logic to a personal space. You cannot allow testing
1028
01:07:23,360 --> 01:07:28,000
in production and these enforced boundaries are the only way to prevent the mistakes that generate
1029
01:07:28,000 --> 01:07:33,120
long term technical debt. Your second priority is establishing fin ops as a permanent discipline
1030
01:07:33,120 --> 01:07:36,640
because cost optimization is a way of working rather than a one time project.
1031
01:07:37,280 --> 01:07:42,080
You need to start by forming a monthly cost review board where engineering, finance and operations
1032
01:07:42,080 --> 01:07:45,920
all sit in the same room to have the same conversation. They need to look at what was spent,
1033
01:07:45,920 --> 01:07:51,280
why it was spent and how the forecast has changed since the last meeting. This isn't a boring
1034
01:07:51,280 --> 01:07:56,480
compliance meeting but a high intensity working session where anomalies are investigated and patterns
1035
01:07:56,480 --> 01:08:01,360
are corrected on the spot. Every quarter you must rebalance your reserved instances and savings
1036
01:08:01,360 --> 01:08:06,000
plans by measuring your actual usage against your existing commitments. You don't just buy a three
1037
01:08:06,000 --> 01:08:10,480
year commitment and walk away. You have to understand which workloads are steady state and which ones
1038
01:08:10,480 --> 01:08:15,920
are actually delivering value. You adjust your strategy every 90 days based on what the data is telling
1039
01:08:15,920 --> 01:08:20,560
you about your actual consumption. You also need to automate your license rationalization so that
1040
01:08:20,560 --> 01:08:25,120
audits of M365 and power platform usage happen every single night. You shouldn't be doing this
1041
01:08:25,120 --> 01:08:29,520
manually when you can have tools running in the background that deliver fresh data to your desk
1042
01:08:29,520 --> 01:08:34,880
every morning. The organization then acts on this data by rebalancing over licensed users and
1043
01:08:34,880 --> 01:08:39,840
marking inactive applications for immediate deletion. The final piece of Finops is implementing a
1044
01:08:39,840 --> 01:08:44,720
charge back model so that every team sees their own consumption as a direct cost to their budget.
1045
01:08:44,720 --> 01:08:49,040
When a team is forced to look at their own bill their behavior changes naturally because they
1046
01:08:49,040 --> 01:08:54,160
finally understand the financial consequences of their architectural choices. Your third priority is
1047
01:08:54,160 --> 01:08:58,320
the consolidation strategy which should be viewed as a 12 month road map rather than a quick fix
1048
01:08:58,320 --> 01:09:03,120
for a single quarter. Start with power platform environment consolidation by reducing your footprint
1049
01:09:03,120 --> 01:09:08,320
and implementing strict life cycle policies for every app. When an app becomes inactive it gets deleted
1050
01:09:08,320 --> 01:09:12,880
and when a connector violates governance it gets blocked by the system. This step alone is usually
1051
01:09:12,880 --> 01:09:18,160
enough to reclaim 30 to 50% of your power platforms spend by eliminating the noise. Then move to
1052
01:09:18,160 --> 01:09:23,360
M365 license right sizing by auditing your utilization and rebalancing your seats based on the actual
1053
01:09:23,360 --> 01:09:28,880
roles of your employees. Use e5 for the people who actually need the security features e3 for your
1054
01:09:28,880 --> 01:09:34,160
knowledge workers and e3 for the front line staff. By eliminating redundant add-ons you can sustain a
1055
01:09:34,160 --> 01:09:39,680
cost reduction of up to 28% indefinitely. The Azure landing zone enforcement comes next where you
1056
01:09:39,680 --> 01:09:44,080
move to a hub spoke architecture and policy driven provisioning for every new subscription.
1057
01:09:44,080 --> 01:09:48,880
This ensures that every new resource inherits your security and cost baselines automatically
1058
01:09:48,880 --> 01:09:54,320
leading to a consistent reduction in infrastructure costs. Your fourth priority is co-pilot readiness
1059
01:09:54,320 --> 01:09:59,040
which is really just a matter of fixing your data hygiene before you try to scale AI.
1060
01:09:59,040 --> 01:10:03,200
Enforce your sensitivity labeling and clean up your sharepoint sites by removing often
1061
01:10:03,200 --> 01:10:08,400
locations and consolidating duplicate files. You have to enforce your retention policies now
1062
01:10:08,400 --> 01:10:12,960
or the AI will simply surface the garbage that you should have deleted years ago. Run your pilot
1063
01:10:12,960 --> 01:10:17,840
governance by giving co-pilot to 400 power users first rather than dumping it on the entire
1064
01:10:17,840 --> 01:10:21,920
organization at once. You need to measure the adoption and the ROI while keeping a very close
1065
01:10:21,920 --> 01:10:26,640
eye on any unintended data exposure. Finally you must enforce hard quotas on tokens per user
1066
01:10:26,640 --> 01:10:31,520
and per application to prevent a massive unexpected bill at the end of the month. This prevents the
1067
01:10:31,520 --> 01:10:36,560
$300,000 surprises before they have a chance to hit your budget. The timeline for this is 90 days
1068
01:10:36,560 --> 01:10:41,840
for the foundation, six months for the Finops discipline and a full year for total consolidation.
1069
01:10:41,840 --> 01:10:46,880
If you follow this path you can expect a 35% cost reduction by month six that stays with you
1070
01:10:46,880 --> 01:10:51,600
for the long haul. Execution will always be theory so you need to start this process on Monday morning
1071
01:10:51,600 --> 01:10:56,960
by auditing your state and enforcing your first policy. Build the foundation and the millions in
1072
01:10:56,960 --> 01:11:03,520
savings will follow. The inevitable outcome. Why this becomes your competitive advantage? We have
1073
01:11:03,520 --> 01:11:07,840
spent a lot of time discussing cost but focusing only on the bill is a mistake. The organizations
1074
01:11:07,840 --> 01:11:11,920
that successfully engineered for determinism did not just save millions of dollars. They gained
1075
01:11:11,920 --> 01:11:16,800
a compounding operational advantage that their competitors simply cannot match. When you move from
1076
01:11:16,800 --> 01:11:22,000
a probabilistic mess to a deterministic system, provisioning time drops from weeks to mere hours.
1077
01:11:22,000 --> 01:11:26,080
Innovation accelerates because teams are no longer sitting around waiting for infrastructure
1078
01:11:26,080 --> 01:11:30,560
requests to clear a bureaucratic hurdle. Instead the infrastructure arrives pre-configured and
1079
01:11:30,560 --> 01:11:35,360
pre-governed which means your developers can focus on customizing tools rather than creating them
1080
01:11:35,360 --> 01:11:39,680
from scratch. That is the difference between moving at the speed of a committee and moving at
1081
01:11:39,680 --> 01:11:44,720
the speed of the market. Compliance also stops being a quarterly fire drill and becomes a structural
1082
01:11:44,720 --> 01:11:49,040
reality. You no longer have to scramble three months before an audit to gather evidence because
1083
01:11:49,040 --> 01:11:53,680
the system has been continuously collecting, logging and monitoring that data since day one.
1084
01:11:53,680 --> 01:11:58,000
When the auditor finally arrives you simply hand over the data without having to reconstruct
1085
01:11:58,000 --> 01:12:02,560
history or explain away embarrassing gaps in your records. The governance was built into the
1086
01:12:02,560 --> 01:12:06,720
foundation so the compliance is automatic. Your incident recovery time improves significantly
1087
01:12:06,720 --> 01:12:11,280
because this model ruthlessly eliminates unmanaged workloads. You won't find any zombie VMs
1088
01:12:11,280 --> 01:12:16,240
that nobody remembers or orphaned applications that no one actually owns because everything is tagged,
1089
01:12:16,240 --> 01:12:20,240
governed and visible. You can actually see the blast radius and understand the dependencies when
1090
01:12:20,240 --> 01:12:24,640
something inevitably breaks. Recovery happens faster and downtime stays shorter which ensures
1091
01:12:24,640 --> 01:12:28,880
that the actual business impact remains as small as possible. Security posture improves because
1092
01:12:28,880 --> 01:12:32,720
you are finally enforcing your assumptions at the control plane level. You cannot accidentally
1093
01:12:32,720 --> 01:12:38,320
grant excessive permissions when role-based access control is hard coded to enforce least privilege.
1094
01:12:38,320 --> 01:12:43,120
You cannot accidentally expose sensitive data when labeling is mandatory and you cannot deploy
1095
01:12:43,120 --> 01:12:47,600
to production from an insecure endpoint when conditional access is standing in the way. This is
1096
01:12:47,600 --> 01:12:52,720
an aspirational security it is structural enforcement by the system itself. Consider a real case study
1097
01:12:52,720 --> 01:12:57,040
from an enterprise that fully committed to this architectural model. Their incident response time
1098
01:12:57,040 --> 01:13:02,400
dropped by 60% not because the humans got faster but because the architecture made the incident simpler
1099
01:13:02,400 --> 01:13:09,040
to solve. By eliminating unmanaged workloads and ensuring complete visibility they understood exactly
1100
01:13:09,040 --> 01:13:14,160
what was happening the moment it started. That 60% faster recovery is a massive competitive advantage.
1101
01:13:14,160 --> 01:13:20,160
Another enterprise saw their audit compliance jump from 62% to 98% without hiring a single new compliance
1102
01:13:20,160 --> 01:13:24,800
officer. They achieved this by making it architecturally impossible to deviate from the rules,
1103
01:13:24,800 --> 01:13:30,640
turning governance into the default state rather than a rare exception. Maintaining 98% compliance
1104
01:13:30,640 --> 01:13:34,960
without increasing your administrative overhead is how you build a moat. A third enterprise managed
1105
01:13:34,960 --> 01:13:39,920
to reduce their provisioning time from 21 days down to just 3. They didn't do this by cracking a
1106
01:13:39,920 --> 01:13:44,400
whip over their staff. They did it by automating the process and making the right configuration the
1107
01:13:44,400 --> 01:13:49,360
only configuration available. By eliminating the endless approval cycles that slow everything down
1108
01:13:49,360 --> 01:13:53,920
they became 7 times faster than they were the year before. This competitive advantage compounds
1109
01:13:53,920 --> 01:13:58,800
because cost is never the only metric that improves. Reliability security and speed all trend
1110
01:13:58,800 --> 01:14:04,560
upward simultaneously. An organization that engineers for determinism doesn't just spend less money.
1111
01:14:04,560 --> 01:14:10,160
It operates with more precision, it moves faster, fails safer and innovates with a level of confidence
1112
01:14:10,160 --> 01:14:15,280
that a chaotic organization can never achieve. The market advantage is clear while your competitors are
1113
01:14:15,280 --> 01:14:20,480
busy negotiating for 5% discounts you are busy engineering waste out of your entire system.
1114
01:14:20,480 --> 01:14:25,040
While they struggle with resource sprawl you are operating with consolidation. While they react
1115
01:14:25,040 --> 01:14:29,680
to problems you are preventing them from ever occurring. That is the fundamental difference between
1116
01:14:29,680 --> 01:14:35,280
simple cost optimization and true architectural excellence. There is also a subtle but profound
1117
01:14:35,280 --> 01:14:40,000
talent advantage to this approach. High level engineers want to work on deterministic systems where
1118
01:14:40,000 --> 01:14:44,400
the architecture actually makes sense and the defaults are correct. They don't want to spend their
1119
01:14:44,400 --> 01:14:49,600
careers in chaotic environments where every deployment is a negotiation and every monthly bill is
1120
01:14:49,600 --> 01:14:54,560
an incomprehensible surprise. The organizations that prioritize architectural discipline attract and
1121
01:14:54,560 --> 01:14:59,360
retain the best talent in the industry. Ultimately your cloud becomes a managed asset rather than a
1122
01:14:59,360 --> 01:15:04,000
financial black hole. It stops being a mystery that grows unpredictably and becomes something you can
1123
01:15:04,000 --> 01:15:08,400
actually control in forecast. This gives you the strategic ability to make decisions based on
1124
01:15:08,400 --> 01:15:13,200
hard data instead of just guessing what next month's invoice might look like. The cynical
1125
01:15:13,200 --> 01:15:17,200
architects final observation is that you don't actually have a cloud strategy problem. You have an
1126
01:15:17,200 --> 01:15:22,320
architectural discipline problem. If you fix the discipline, the cost, reliability and security will
1127
01:15:22,320 --> 01:15:26,240
all follow naturally. Everything flows from the architecture and everything depends on whether you
1128
01:15:26,240 --> 01:15:31,200
have engineered for determinism or simply left your environment to chance. The organizations that
1129
01:15:31,200 --> 01:15:35,920
reclaimed millions are the ones that made these rules structural. Conclusion, the millions are not
1130
01:15:35,920 --> 01:15:40,640
hidden. The millions of dollars you're looking for are not hidden in a better contract negotiation
1131
01:15:40,640 --> 01:15:45,600
or a special discount. They are embedded in every unmanaged resource, every overlicensed seat and
1132
01:15:45,600 --> 01:15:50,480
every ungoverned workload currently running in your environment. The enterprises that successfully
1133
01:15:50,480 --> 01:15:55,520
reclaimed that capital did not just optimize their spending, they engineered for determinism. They
1134
01:15:55,520 --> 01:16:00,320
moved away from a model of probabilistic waste and toward a model of deterministic efficiency.
1135
01:16:00,320 --> 01:16:05,360
This is not a simple cost-cutting exercise. It is a commitment to architectural excellence.
1136
01:16:05,360 --> 01:16:09,520
If you want to see those millions in savings, you have to start with governance. Once you fix the
1137
01:16:09,520 --> 01:16:15,760
foundation, everything else follows. Subscribe to the M365FM podcast before you leave today.
1138
01:16:15,760 --> 01:16:21,200
Every episode breaks down the architectural realities of Microsoft 365, Copilot, and Azure
1139
01:16:21,200 --> 01:16:25,760
Security for the modern workplace. We help IT leaders stay ahead of a shifting ecosystem.
1140
01:16:25,760 --> 01:16:30,240
You should also connect with me, Mirko Peters on LinkedIn, to help identify our next deep dive.
1141
01:16:30,240 --> 01:16:34,160
Tell me which architectural failure is costing your company millions. Let's talk about it.

Founder of m365.fm, m365.show and m365con.net
Mirko Peters is a Microsoft 365 expert, content creator, and founder of m365.fm, a platform dedicated to sharing practical insights on modern workplace technologies. His work focuses on Microsoft 365 governance, security, collaboration, and real-world implementation strategies.
Through his podcast and written content, Mirko provides hands-on guidance for IT professionals, architects, and business leaders navigating the complexities of Microsoft 365. He is known for translating complex topics into clear, actionable advice, often highlighting common mistakes and overlooked risks in real-world environments.
With a strong emphasis on community contribution and knowledge sharing, Mirko is actively building a platform that connects experts, shares experiences, and helps organizations get the most out of their Microsoft 365 investments.